
반응형
스프링 배치 청크 프로세스
기본개념
- 2차원 데이터(표)로 표현된 유형의 파일을 처리하는 ItemReader
- 일반적으로 고정 위치로 정의된 데이터 필드나 특수 문자에 의해 구별된 데이터의 행을 읽는다
- Resource 와 LineMapper 두 가지 요소가 필요하다
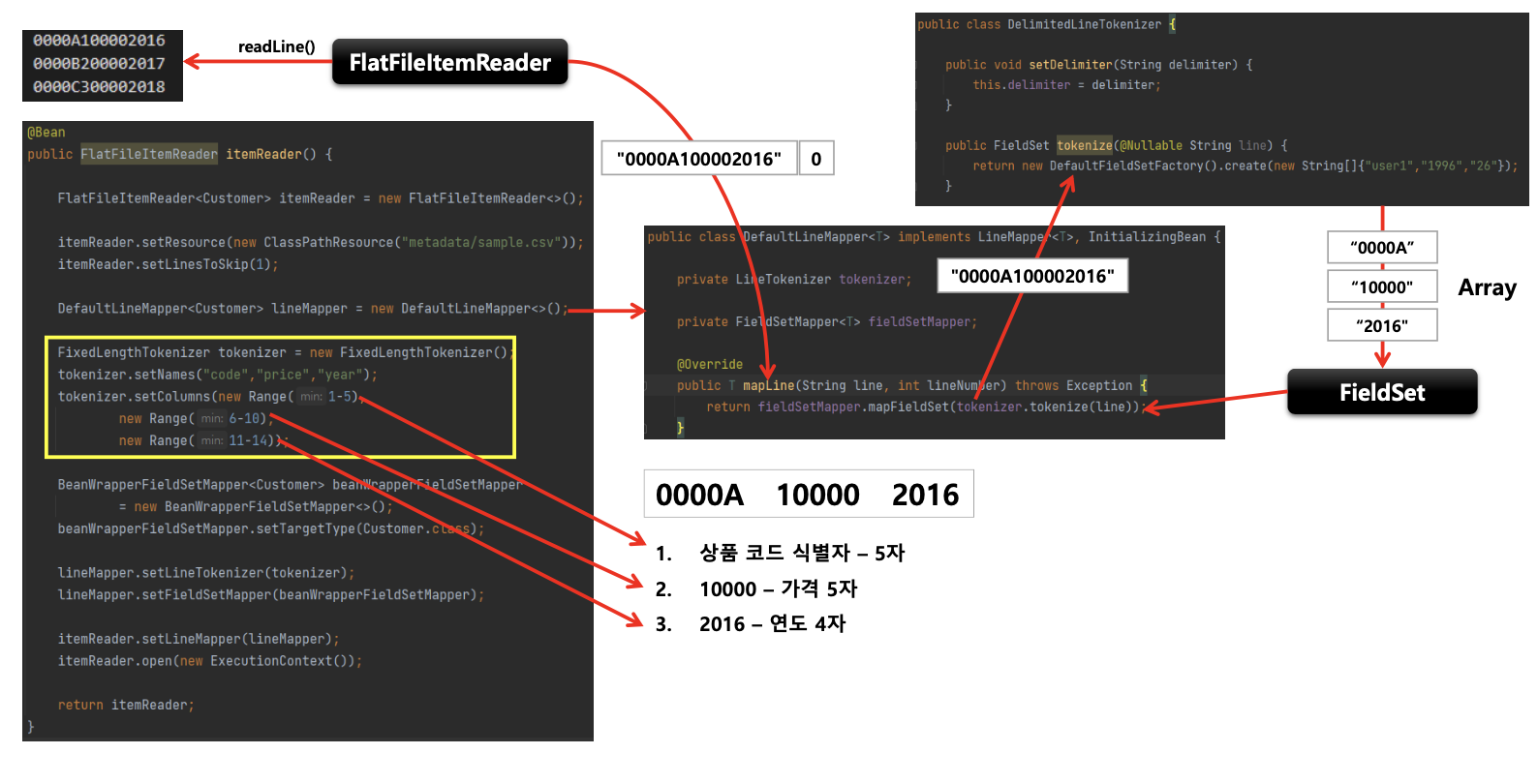
구조

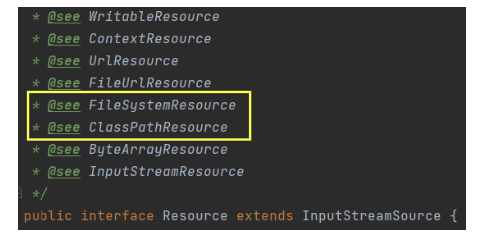
Resource
- FileSystemResource – new FileSystemResource(“resource/path/config.xml”)
- ClassPathResource – new ClassPathResource(“classpath:path/config.xml)
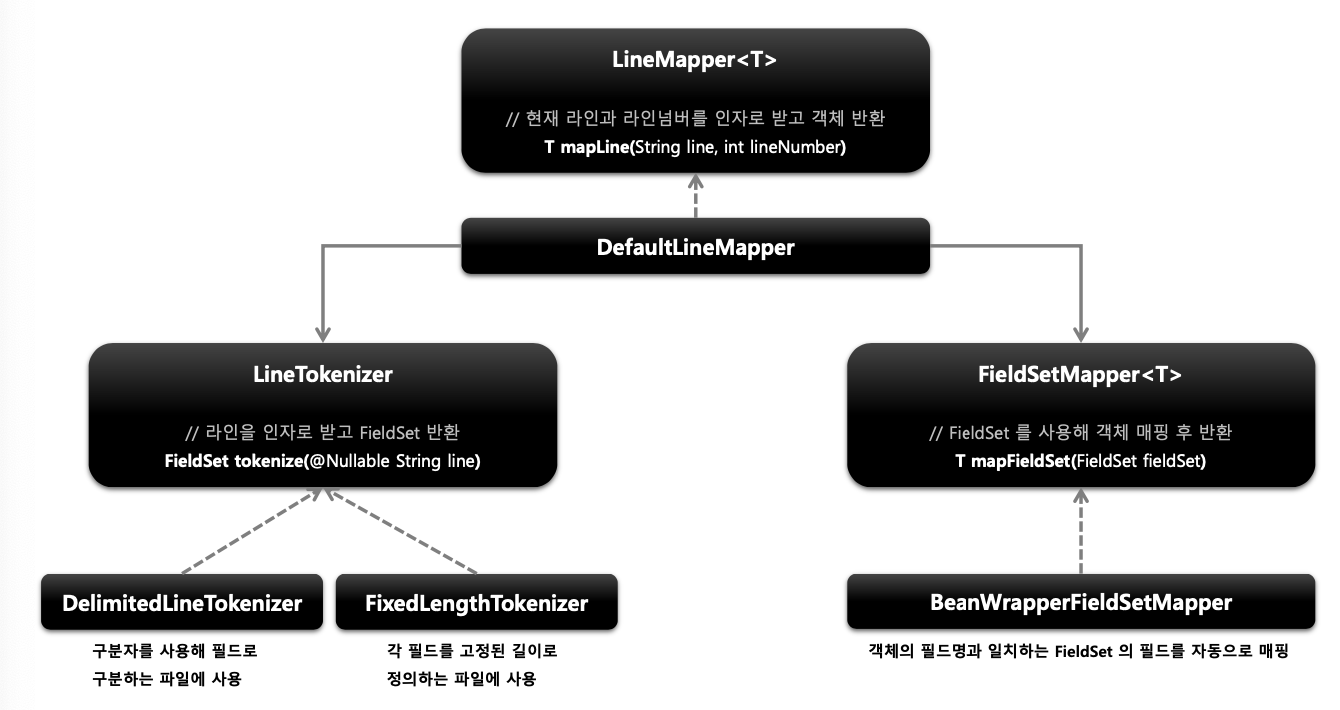
LineMapper
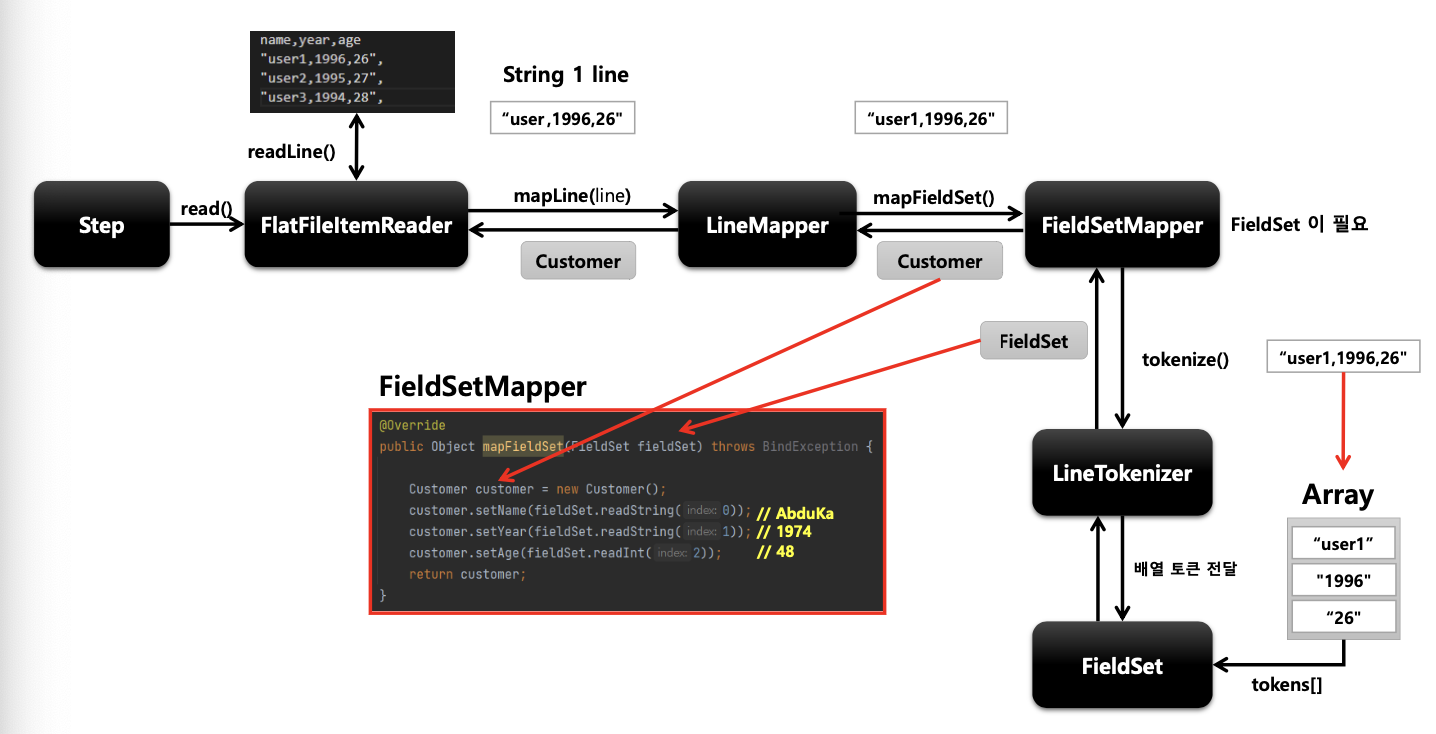
- 파일의 라인 한줄을 Object 로 변환해서 FlatFileItemReader 로 리턴한다
- 단순히 문자열을 받기 때문에 문자열을 토큰화해서 객체로 매핑하는 과정이 필요하다
- LineTokenizer 와 FieldSetMapper 를 사용해서 처리한다
- FieldSet
- 라인을 필드로 구분해서 만든 배열 토큰을 전달하면 토큰 필드를 참조 할수 있도록 한다
- JDBC 의 ResultSet 과 유사하다 ex) fs.readString(0), fs.readString(“name”)
- LineTokenizer
- 입력받은 라인을 FieldSet 으로 변환해서 리턴한다
- 파일마다 형식이 다르기 때문에 문자열을 FieldSet 으로 변환하는 작업을 추상화시켜야 한다.
- FieldSetMapper
- FieldSet 객체를 받아서 원하는 객체로 매핑해서 리턴한다
- JdbcTemplate 의 RowMapper 와 동일한 패턴을 사용한다
예제 코드
package com.example.springbatch_8_1_flatfileitemreader;
import lombok.RequiredArgsConstructor;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import java.util.List;
/**
* packageName : com.example.springbatch_8_1_flatfileitemreader
* fileName : FlatFilesConfiguration
* author : namhyeop
* date : 2022/08/08
* description :
* FlatFilesItemReader 예제
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/08 namhyeop 최초 생성
*/
@RequiredArgsConstructor
@Configuration
public class FlatFilesConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job job(){
return jobBuilderFactory.get("batchJob")
.start(step1())
.next(step2())
.build();
}
@Bean
public Step step1(){
return stepBuilderFactory.get("step1")
.<String, String>chunk(5)
.reader(itemReader())
.writer(new ItemWriter<String>() {
@Override
public void write(List<? extends String> items) throws Exception {
System.out.println("items = " + items);
}
}).build();
}
@Bean
public Step step2(){
return stepBuilderFactory.get("step2")
.tasklet((contribution, chunkContext) -> {
System.out.println("step2 has executed");
return RepeatStatus.FINISHED;
}).build();
}
@Bean
public ItemReader itemReader(){
FlatFileItemReader<Customer> itemReader = new FlatFileItemReader<Customer>();
itemReader.setResource(new ClassPathResource("/customer.csv"));
DefaultLineMapper<Customer> lineMapper = new DefaultLineMapper<>();
lineMapper.setLineTokenizer(new DelimitedLineTokenizer());
lineMapper.setFieldSetMapper(new CustomerFieldSetMapper());
itemReader.setLineMapper(lineMapper);
//customer.csv 맨윗줄 한줄 생략
itemReader.setLinesToSkip(1);
return itemReader;
}
}package com.example.springbatch_8_1_flatfileitemreader;
import org.springframework.batch.item.file.LineMapper;
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.LineTokenizer;
/**
* packageName : com.example.springbatch_8_1_flatfileitemreader
* fileName : DefaultLineMapper
* author : namhyeop
* date : 2022/08/08
* description :
* DefaultLineMapper 예제, customer의 정보를 읽고 token화 하기 위해서 필요
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/08 namhyeop 최초 생성
*/
public class DefaultLineMapper <T> implements LineMapper {
private LineTokenizer tokenizer;
private FieldSetMapper<T> fieldSetMapper;
@Override
public T mapLine(String line, int lineNumber) throws Exception{
return fieldSetMapper.mapFieldSet(tokenizer.tokenize(line));
}
public void setLineTokenizer(LineTokenizer tokenizer){
this.tokenizer = tokenizer;
}
public void setFieldSetMapper(FieldSetMapper<T> fieldSetMapper){
this.fieldSetMapper = fieldSetMapper;
}
}package com.example.springbatch_8_1_flatfileitemreader;
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.FieldSet;
import org.springframework.validation.BindException;
/**
* packageName : com.example.springbatch_8_1_flatfileitemreader
* fileName : CustomerFieldSetMapper
* author : namhyeop
* date : 2022/08/08
* description :
* Customer 정보를 읽는 자료형 설정
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/08 namhyeop 최초 생성
*/
public class CustomerFieldSetMapper implements FieldSetMapper<Customer> {
@Override
public Customer mapFieldSet(FieldSet fs) throws BindException {
if(fs == null){
return null;
}
Customer customer = new Customer();
customer.setName(fs.readString(0));
customer.setAge(fs.readInt(1));
customer.setYear(fs.readString(2));
return customer;
}
}package com.example.springbatch_8_1_flatfileitemreader;
import lombok.Data;
/**
* packageName : com.example.springbatch_8_1_flatfileitemreader
* fileName : Customer
* author : namhyeop
* date : 2022/08/08
* description :
* Customer Dto
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/08d namhyeop 최초 생성
*/
@Data
public class Customer {
private String name;
private int age;
private String year;
}DelimitedLineTokenizer
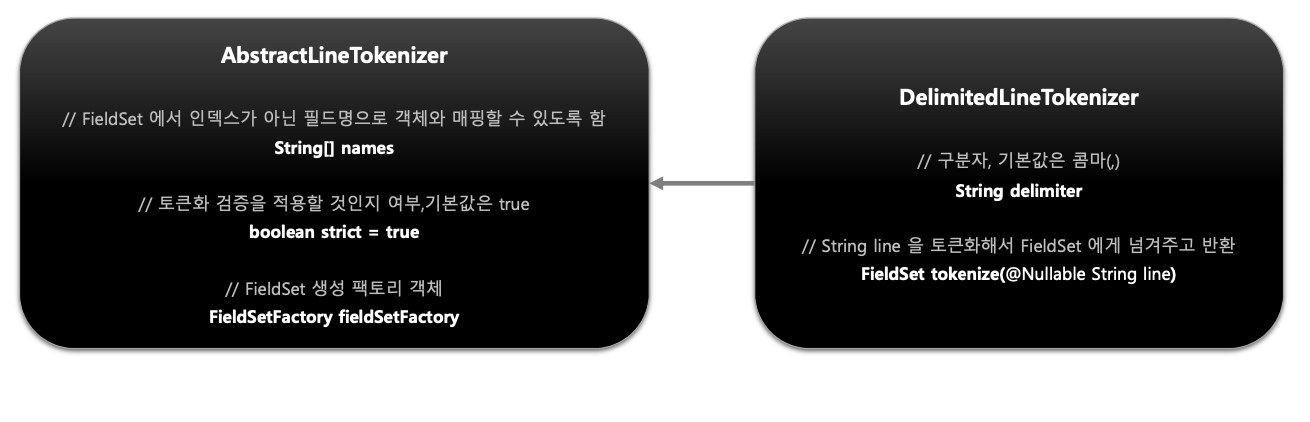
기본개념
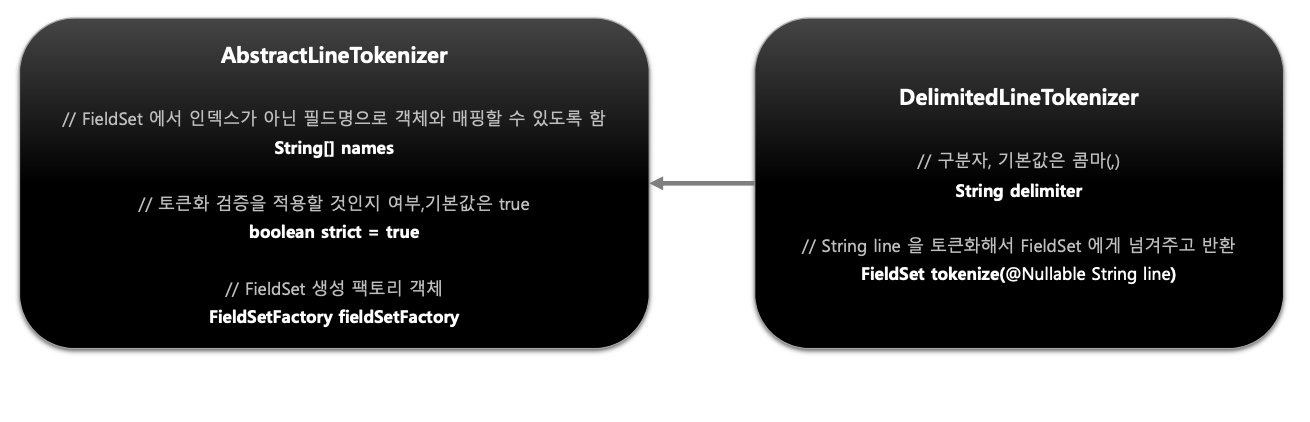
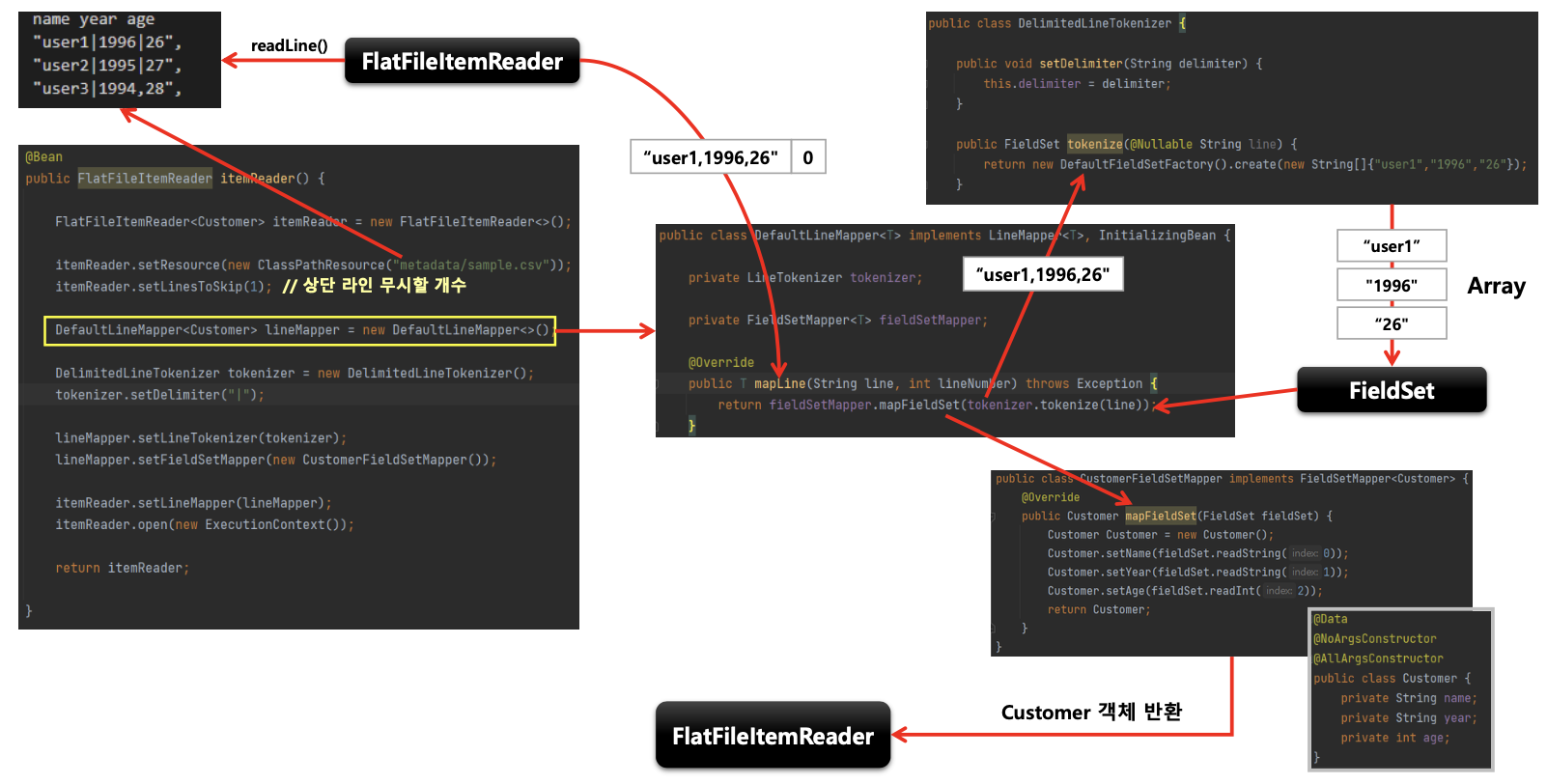
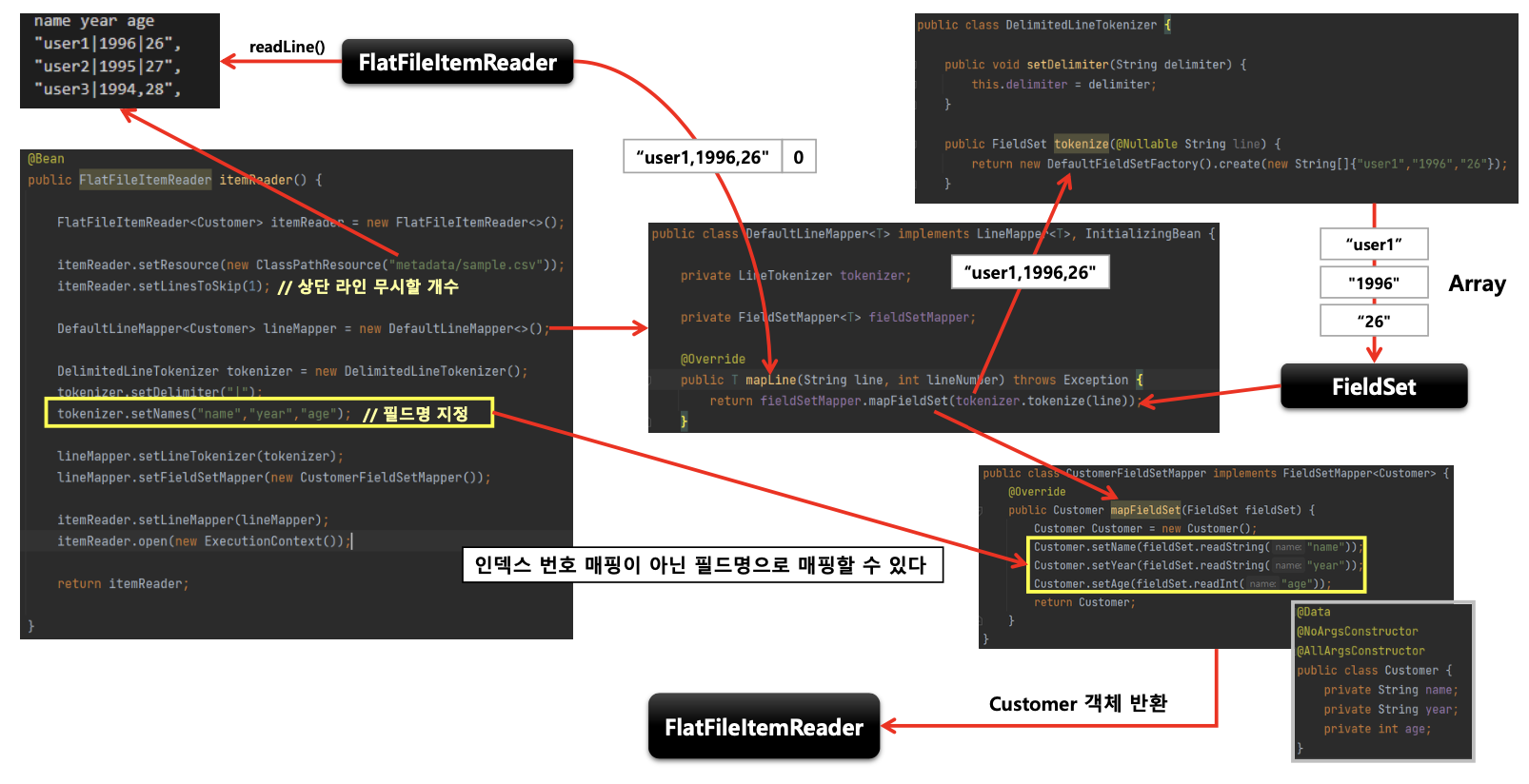
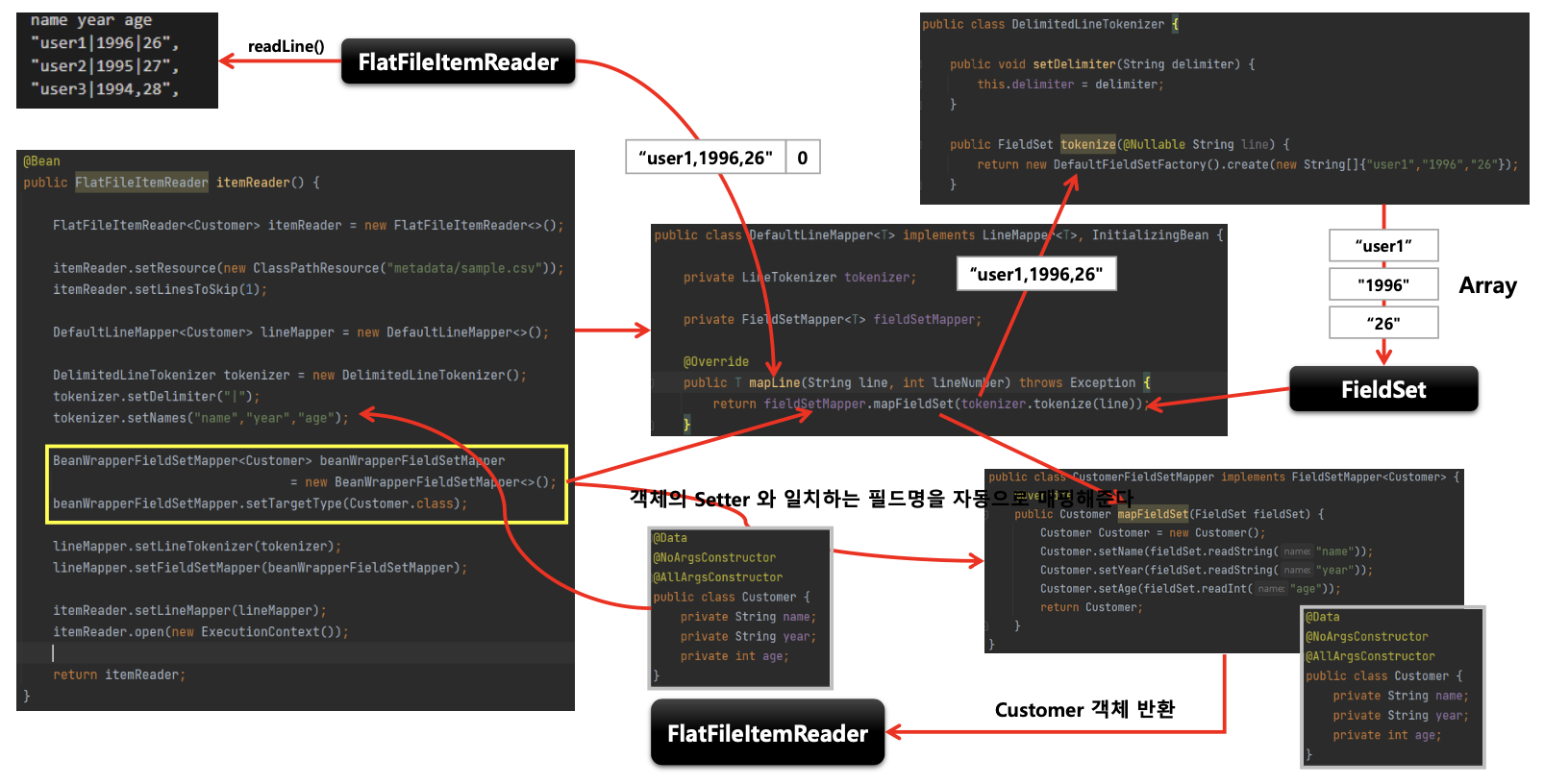
- 한 개 라인의 String을 구분자 기준으로 나누어 토큰화 하는 방식
구조
예제 코드
package com.example.springbatch_8_2_flatfileitemreader_delimetedlinetokenizer;
import lombok.RequiredArgsConstructor;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.file.builder.FlatFileItemReaderBuilder;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import java.util.List;
/**
* packageName : com.example.springbatch_8_1_flatfileitemreader
* fileName : FlatFilesConfiguration
* author : namhyeop
* date : 2022/08/08
* description :
* FlatFilesItemReader-delimetedlinetokenizer 예제
* 이전 8-1에서는 직접 delimitedlinetokenizer를 구현해서 사용했다면 이번에는 실제 존재하는 라이브러리를 itemReadr에 적용한다.
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/08 namhyeop 최초 생성
*/
@RequiredArgsConstructor
@Configuration
public class FlatFilesConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job job(){
return jobBuilderFactory.get("batchJob")
.start(step1())
.next(step2())
.build();
}
@Bean
public Step step1(){
return stepBuilderFactory.get("step1")
.<String, String>chunk(3)
.reader(itemReader())
.writer(new ItemWriter<String>() {
@Override
public void write(List<? extends String> items) throws Exception {
System.out.println("items = " + items);
}
}).build();
}
@Bean
public Step step2(){
return stepBuilderFactory.get("step2")
.tasklet((contribution, chunkContext) -> {
System.out.println("step2 has executed");
return RepeatStatus.FINISHED;
}).build();
}
@Bean
public ItemReader itemReader(){
return new FlatFileItemReaderBuilder<Customer>()
.name("flatFile")
.resource(new ClassPathResource("customer.csv"))
//1.아래의 직접 만든 CustomerFieldSeMapper를 사용하지 않고 Batch의 BeanWrapperFieldSetMapper를 사용
.fieldSetMapper(new BeanWrapperFieldSetMapper<>())
//2.BeanWrapperFieldSetMapper를 사용한다면 targetType을 반드시 명시해줘야한다.
.targetType(Customer.class)
// .fieldSetMapper(new CustomerFieldSetMapper())
.linesToSkip(1)
.delimited().delimiter(",")
.names("name","age","year")
.build();
}
}
package com.example.springbatch_8_2_flatfileitemreader_delimetedlinetokenizer;
import lombok.Data;
/**
* packageName : com.example.springbatch_8_1_flatfileitemreader
* fileName : Customer
* author : namhyeop
* date : 2022/08/08
* description :
* Customer Dto
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/08d namhyeop 최초 생성
*/
@Data
public class Customer {
private String name;
private int age;
private String year;
}FixedLengthTokenizer
기본개념

- 한 개 라인의 String을 사용자가 설정한 고정길이 기준으로 나누어 토큰화 하는 방식
- 범위는 문자열 형식으로 설정 할 수 있다
- “1-4"또는 "1-3,4-6,7"또는 "1-2,4-5,7-10”
- 마직막 범위가 열려 있으면 나머지 행이 해당 열로 읽혀진다
구조
package com.example.springbatch_8_3_fixedlengthtokenizer;
import lombok.RequiredArgsConstructor;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.builder.FlatFileItemReaderBuilder;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.transform.Range;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.FileSystemResource;
import java.util.List;
/**
* packageName : com.example.springbatch_8_3_fixedlengthtokenizer
* fileName : FlatFilesFixedLengthConfiguration
* author : namhyeop
* date : 2022/08/11
* description :
* Reader를 문자열의 길이로 읽어오는 예
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/11 namhyeop 최초 생성
*/
@RequiredArgsConstructor
@Configuration
public class FlatFilesFixedLengthConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job job(){
return jobBuilderFactory.get("batchJob")
.start(step1())
.next(step2())
.build();
}
@Bean
public Step step1(){
return stepBuilderFactory.get("step1")
.<String,String>chunk(3)
.reader(itemReader())
.writer(new ItemWriter<String>() {
@Override
public void write(List items) throws Exception {
items.forEach(item -> System.out.println(item));
System.out.println("==========");
}
}).build();
}
public FlatFileItemReader itemReader(){
return new FlatFileItemReaderBuilder<Customer>()
.name("flatFile")
.resource(new FileSystemResource("/Users/namhyeop/Desktop/git자료/Spring_Boot_Study/8.Spring_Batch/SpringBatch_8_3_fixedlengthtokenizer/src/main/resources/customer.txt"))
.fieldSetMapper(new BeanWrapperFieldSetMapper<>())
.targetType(Customer.class)
.linesToSkip(1)
.fixedLength()
.addColumns(new Range(1,5))
.addColumns(new Range(6,9))
.addColumns(new Range(10, 11))
.names("name", "year", "age")
.build();
}
@Bean
public Step step2(){
return stepBuilderFactory.get("step2")
.tasklet((contribution, chunkContext) -> {
System.out.println("step2 has executeed");
return RepeatStatus.FINISHED;
})
.build();
}
}package com.example.springbatch_8_3_fixedlengthtokenizer;
import lombok.Data;
/**
* packageName : com.example.springbatch_8_3_fixedlengthtokenizer
* fileName : Customer
* author : namhyeop
* date : 2022/08/11
* description :
* Customer Dto
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/11 namhyeop 최초 생성
*/
@Data
public class Customer {
private String name;
private int age;
private String year;
}Exception Handling
기본개념
- 라인을 읽거나 토큰화 할 때 발생하는 Parsing 예외를 처리할 수 있도록 예외 계층 제공
- 토큰화 검증을 엄격하게 적용하지 않도록 설정하면 Parsing 예외가 발생하지 않도록 할 수 있
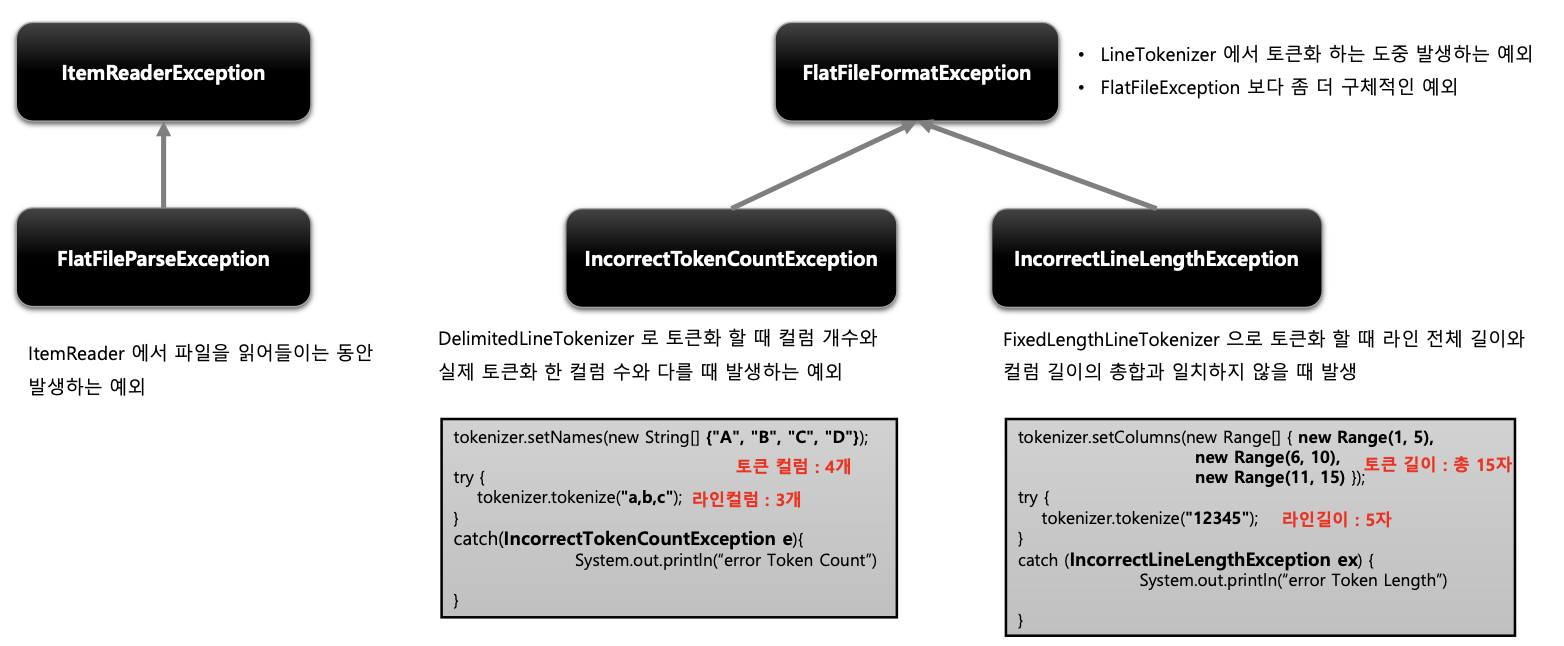
토큰화 검증 기준 설정

- LineTokenizer 의 Strict 속성을 false 로 설정하게 되면 Tokenizer 가 라인 길이를 검증하지 않는다
- Tokenizer 가 라인 길이나 컬럼명을 검증하지 않을 경우 예외가 발생하지 않는다
- FieldSet 은 성공적으로 리턴이 되며 두번째 범위 값은 빈 토큰을 가지게 된다
예제코드
package com.example.springbatch_8_3_fixedlengthtokenizer;
import lombok.RequiredArgsConstructor;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.builder.FlatFileItemReaderBuilder;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.transform.Range;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.FileSystemResource;
import java.util.List;
/**
* packageName : com.example.springbatch_8_3_fixedlengthtokenizer
* fileName : FlatFilesFixedLengthConfiguration
* author : namhyeop
* date : 2022/08/11
* description :
* Exception 설정을 꺼봄으로써 Exeption 예외처리의 존재를 확인하는 예제
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/11 namhyeop 최초 생성
*/
@RequiredArgsConstructor
@Configuration
public class FlatFilesFixedLengthConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job job(){
return jobBuilderFactory.get("batchJob")
.start(step1())
.next(step2())
.build();
}
@Bean
public Step step1(){
return stepBuilderFactory.get("step1")
.<String,String>chunk(3)
.reader(itemReader())
.writer(new ItemWriter<String>() {
@Override
public void write(List items) throws Exception {
items.forEach(item -> System.out.println(item));
System.out.println("==========");
}
}).build();
}
public FlatFileItemReader itemReader(){
return new FlatFileItemReaderBuilder<Customer>()
.name("flatFile")
.resource(new FileSystemResource("/Users/namhyeop/Desktop/git자료/Spring_Boot_Study/8.Spring_Batch/SpringBatch_8_3_fixedlengthtokenizer/src/main/resources/customer.txt"))
.fieldSetMapper(new BeanWrapperFieldSetMapper<>())
.targetType(Customer.class)
.linesToSkip(1)
.fixedLength()
.strict(false)
.addColumns(new Range(1,5))
.addColumns(new Range(6,9))
.addColumns(new Range(10, 11))
.names("name", "year", "age")
.build();
}
@Bean
public Step step2(){
return stepBuilderFactory.get("step2")
.tasklet((contribution, chunkContext) -> {
System.out.println("step2 has executeed");
return RepeatStatus.FINISHED;
})
.build();
}
}package com.example.springbatch_8_3_fixedlengthtokenizer;
import lombok.Data;
/**
* packageName : com.example.springbatch_8_3_fixedlengthtokenizer
* fileName : Customer
* author : namhyeop
* date : 2022/08/11
* description :
* Customer Dto
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/11 namhyeop 최초 생성
*/
@Data
public class Customer {
private String name;
private String year;
private int age;
}XML-StaxEventItemReader
1.JAVA XML API
- DOM 방식
- 문서 전체를 메모리에 로드한 후 Tree 형태로 만들어서 데이터를 처리하는 방식, pull 방식
- 엘리멘트 제어는 유연하나 문서크기가 클 경우 메모리 사용이 많고 속도가 느림
- SAX 방식
- 문서의 항목을 읽을 때 마다 이벤트가 발생하여 데이터를 처리하는 push 방식
- 메모리 비용이 적고 속도가 빠른 장점은 있으나 엘리멘트 제어가 어려움
- StAX 방식 (Streaming API for XML)
- DOM과SAX의장점과단점을보완한API모델로서push와pull을동시에제공함
- XML문서를읽고쓸수있는양방향파서기지원
- XML 파일의 항목에서 항목으로 직접 이동하면서 Stax 파서기를 통해 구문 분석
- 유형
- Iterator API 방식
- XMLEventReader 의 nextEvent() 를 호출해서 이벤트 객체를 가지고 옴
- 이벤트 객체는 XML 태그 유형 (요소, 텍스트, 주석 등)에 대한 정보를 제공함
- Cursor API 방식
- JDBC Resultset 처럼 작동하는 API 로서 XMLStreamReader 는 XML 문서의 다음 요소로 커서를 이동한다
- 커서에서 직접 메서드를 호출하여 현재 이벤트에 대한 자세한 정보를 얻는다
- Iterator API 방식
- Spring-OXM
- 스프링의 Object XML Mapping 기술로 XML 바인딩 기술을 추상화함
- Marshaller
- marshall – 객체를 XML 로 직렬화하는 행위
- Unmarchaller
- unmarshall – XML 을 객체로 역직렬화하는 행위
- Marshaller 와 Unmarshaller 바인딩 기능을 제공하는 오픈소스로 JaxB2, Castor, XmlBeans, Xstream 등이 있다
- Marshaller
- 스프링의 Object XML Mapping 기술로 XML 바인딩 기술을 추상화함
- 스프링 배치는 특정한 XML 바인딩 기술을 강요하지 않고 Spring OXM 에 위임한다
- 바인딩 기술을 제공하는 구현체를 선택해서 처리하도록 한다.
- Spring Batch XML
- 스프링 배치에서는 StAX 방식으로 XML 문서를 처리하는 StaxEventItemReader 를 제공한다
- XML 을 읽어 자바 객체로 매핑하고 자바 객체를 XML 로 쓸 수 있는 트랜잭션 구조를 지원
2.StAX 아키텍처
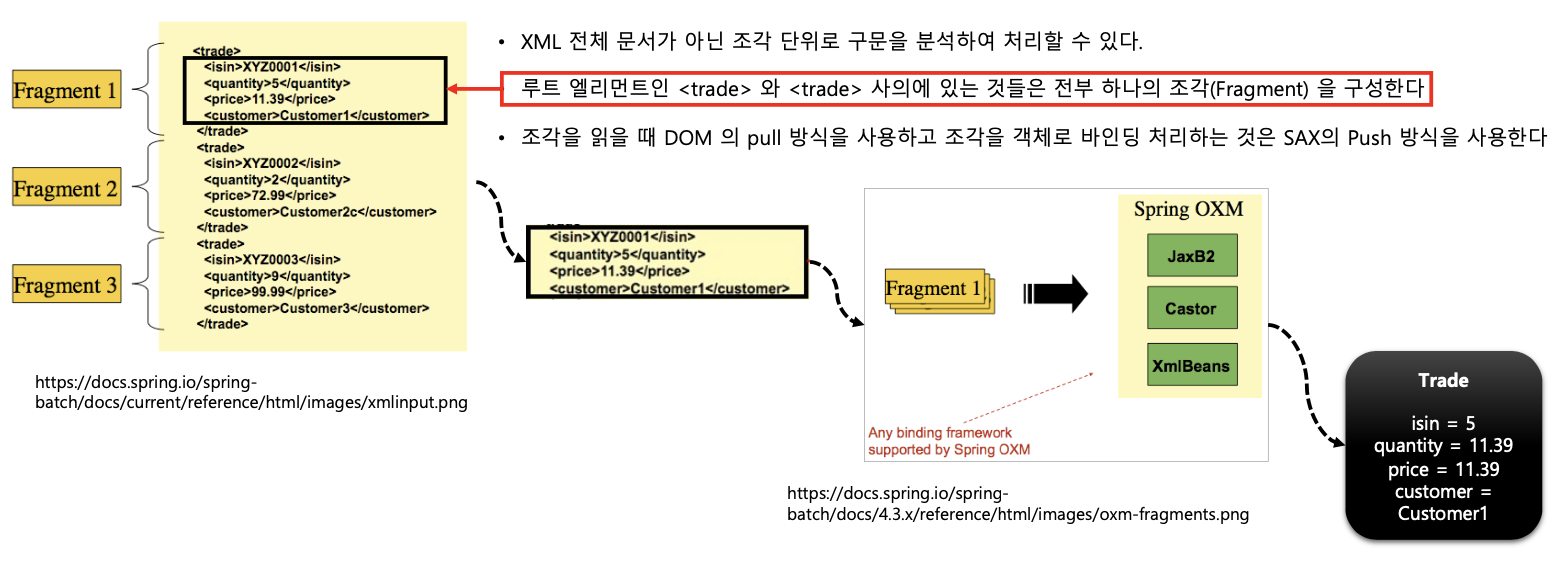
3.API 구조

예제
기본개념
- Stax API 방식으로 데이터를 읽어들이는 ItemReader
- Spring-OXM 과 Xstream 의존성을 추가해야 한다

<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-oxm</artifactId>
<version>5.3.7</version>
</dependency>
<dependency>
<groupId>com.thoughtworks.xstream</groupId>
<artifactId>xstream</artifactId>
<version>1.4.16</version>
</dependency>2.StaxEventItemReader
- 데이터를 읽는 Reader인 StaxEventItemReader에 대해서 살펴본다.
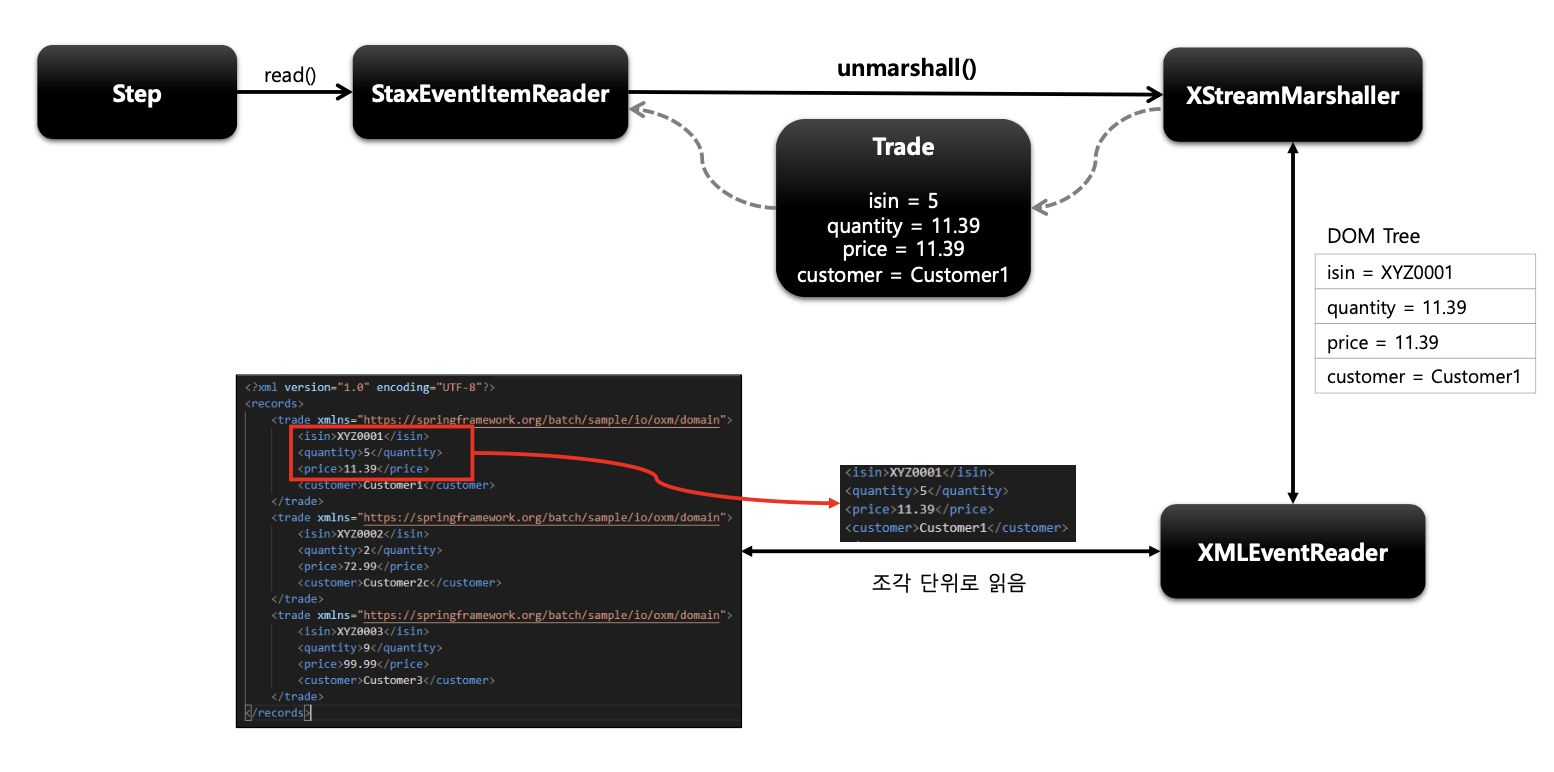
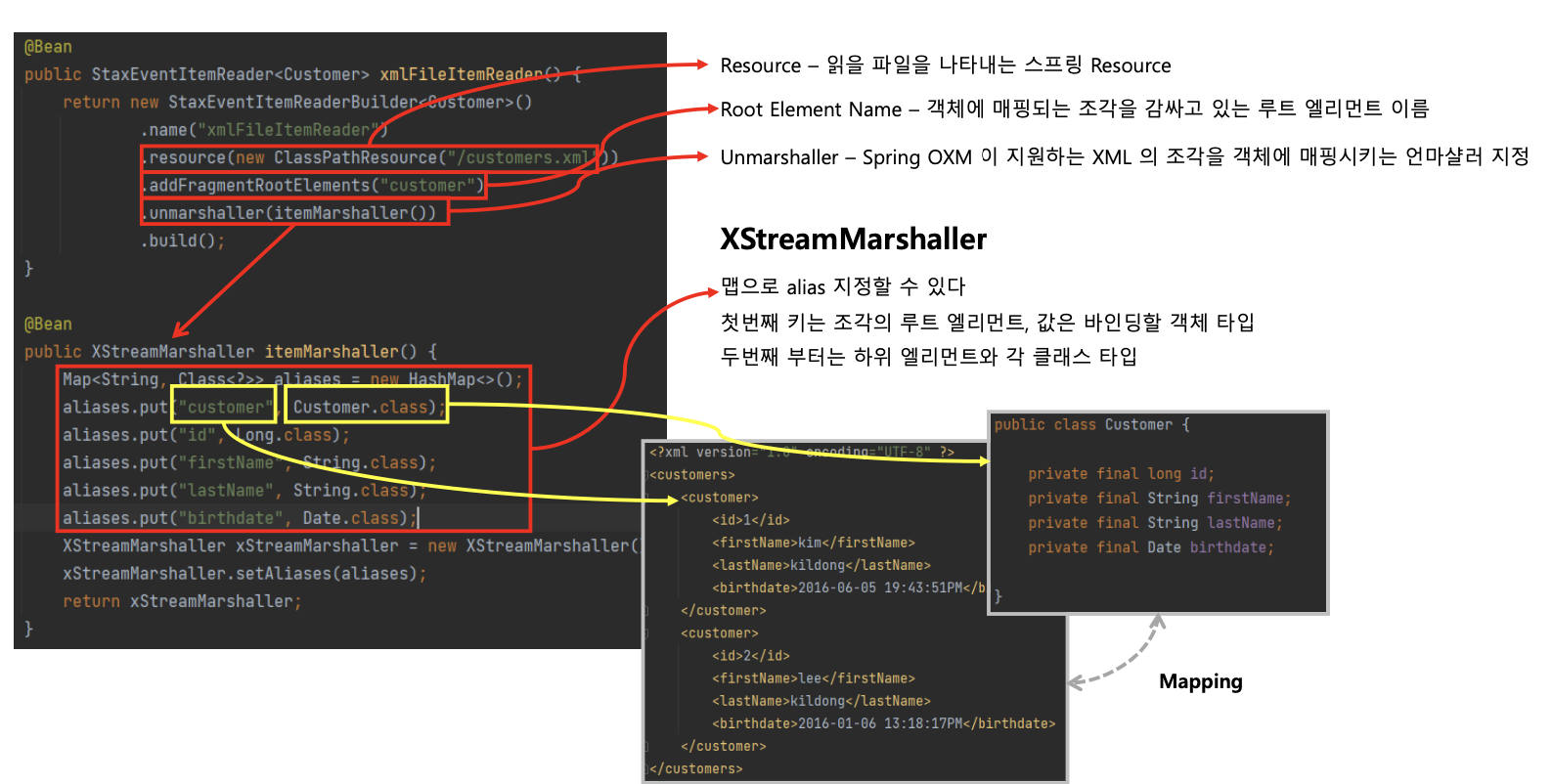
예제코드
package com.example.springbatch_8_5_staxeventitemreader;
import lombok.RequiredArgsConstructor;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.xml.StaxEventItemReader;
import org.springframework.batch.item.xml.builder.StaxEventItemReaderBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.oxm.Unmarshaller;
import org.springframework.oxm.xstream.XStreamMarshaller;
import java.util.HashMap;
import java.util.Map;
/**
* packageName : PACKAGE_NAME
* fileName : com.example.springbatch_8_5_staxeventitemreader.XMLConfiguration
* author : namhyeop
* date : 2022/08/11
* description :
* XML데이터를 객체로 직렬화하는 예제
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/11 namhyeop 최초 생성
*/
@RequiredArgsConstructor
@Configuration
public class XMLConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job job(){
return jobBuilderFactory.get("batchJob")
.incrementer(new RunIdIncrementer())
.start(step1())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
.<Customer, Customer>chunk(3)
.reader(customItemReader())
.writer(customItemWriter())
.build();
}
@Bean
public ItemReader<? extends Customer> customItemReader(){
return new StaxEventItemReaderBuilder<Customer>()
.name("statXml")
.resource(new ClassPathResource("customer.xml"))
//xml에서 데이터를 읽으면서 나눌 속성 명시
.addFragmentRootElements("customer")
.unmarshaller(itemUnmarshaller())
.build();
}
@Bean
public Unmarshaller itemUnmarshaller() {
Map<String, Class<?>> aliases = new HashMap<>();
aliases.put("customer", Customer.class);
aliases.put("id", Long.class);
aliases.put("name", String.class);
aliases.put("age", Integer.class);
XStreamMarshaller xStreamMarshaller = new XStreamMarshaller();
xStreamMarshaller.setAliases(aliases);
return xStreamMarshaller;
}
@Bean
public ItemWriter<Customer> customItemWriter(){
return items->{
for (Customer item : items) {
System.out.println(item.toString());
}
};
}
}package com.example.springbatch_8_5_staxeventitemreader;
import lombok.Data;
/**
* packageName : com.example.springbatch_8_5_staxeventitemreader
* fileName : Customer
* author : namhyeop
* date : 2022/08/11
* description :
* Customer Dto
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/11 namhyeop 최초 생성
*/
@Data
public class Customer {
private final long id;
private final String name ;
private final int age;
}Json - JsonItemReader
기본개념
- Json 데이터의 Parsing 과 Binding 을 JsonObjectReader 인터페이스 구현체에 위임하여 처리하는 ItemReader
두 가지 구현체 제공- JacksonJsonObjectReader
- GsonJsonObjectReader
구조
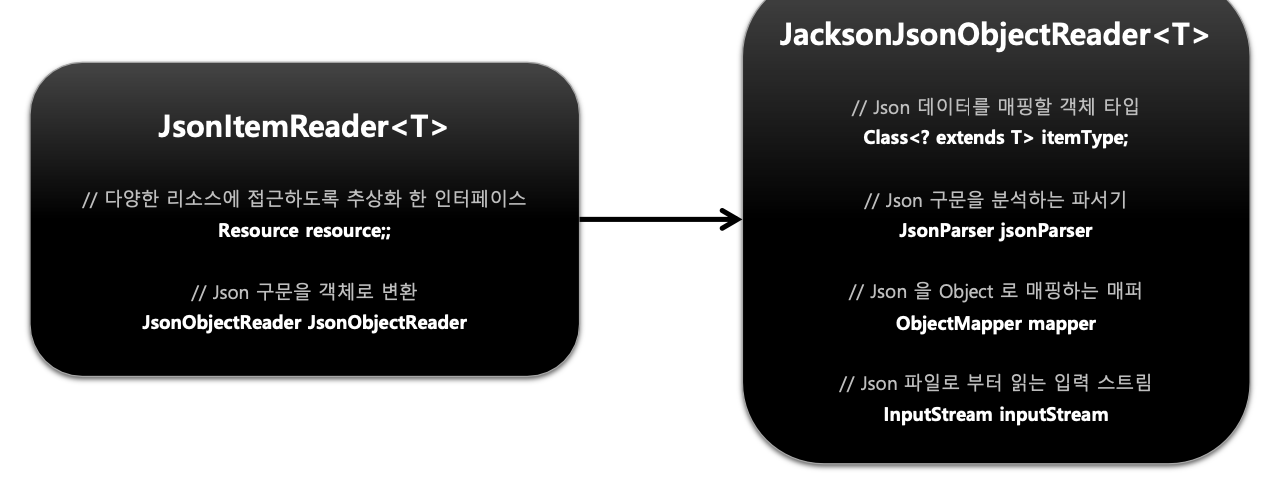
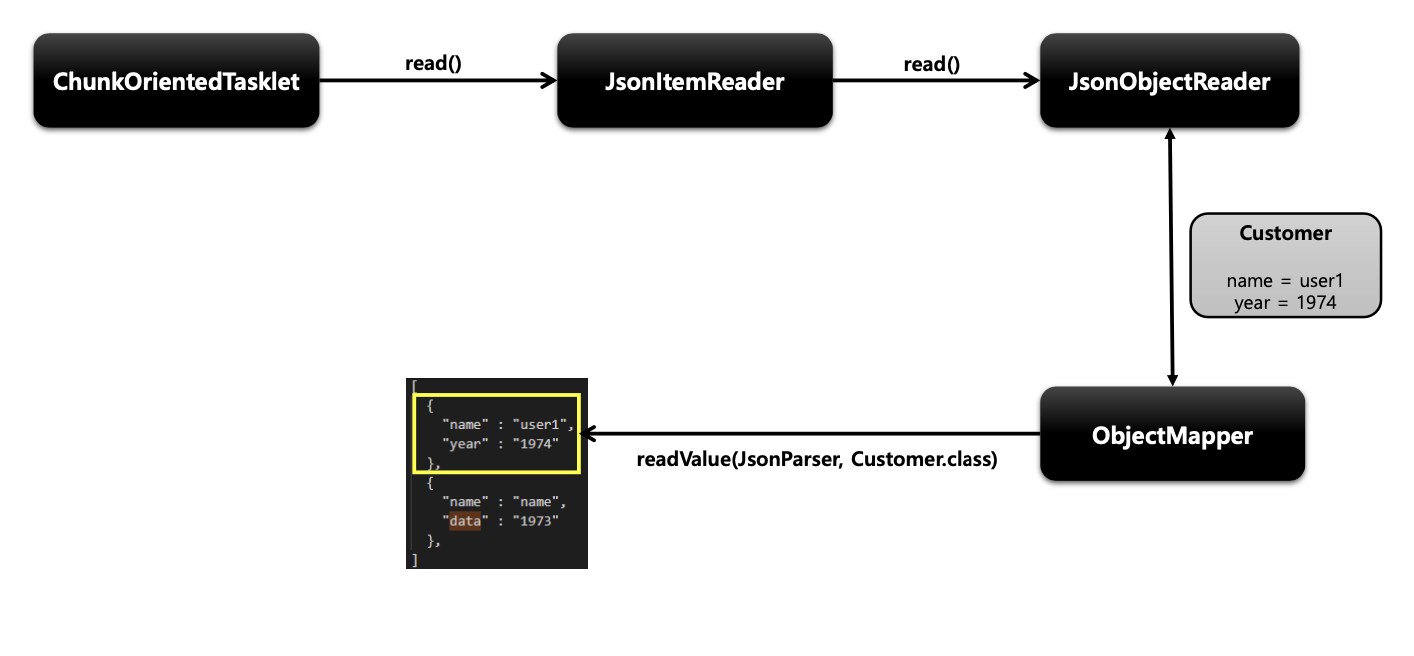
API 설정
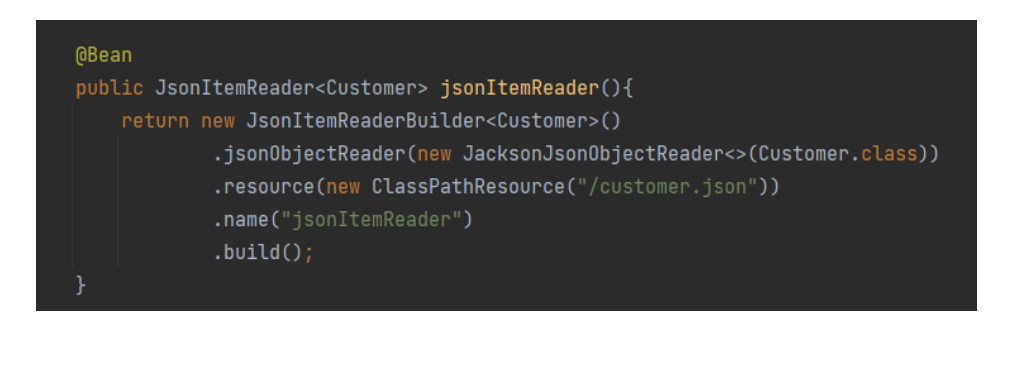
예제코드
package com.example.springbatch_8_6_jsonitemreader;
import lombok.RequiredArgsConstructor;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.json.JacksonJsonObjectReader;
import org.springframework.batch.item.json.builder.JsonItemReaderBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
/**
* packageName : com.example.springbatch_8_6_jsonitemreader
* fileName : JsonConfiguration
* author : namhyeop
* date : 2022/08/11
* description :
* JSON 데이터를 읽어오는 예제
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/11 namhyeop 최초 생성
*/
@RequiredArgsConstructor
@Configuration
public class JsonConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job job(){
return jobBuilderFactory.get("batchJob")
.incrementer(new RunIdIncrementer())
.start(step1())
.build();
}
@Bean
public Step step1(){
return stepBuilderFactory.get("step1")
.<Customer, Customer>chunk(3)
.reader(customItemReader())
.writer(customItemWriter())
.build();
}
@Bean
public ItemReader<? extends Customer> customItemReader(){
return new JsonItemReaderBuilder<Customer>()
.name("jsonReader")
.resource(new ClassPathResource("customer.json"))
.jsonObjectReader(new JacksonJsonObjectReader<>(Customer.class))
.build();
}
@Bean
public ItemWriter<Customer> customItemWriter(){
return items -> {
for(Customer item : items){
System.out.println(item.toString());
}
};
}
}package com.example.springbatch_8_6_jsonitemreader;
import lombok.Data;
/**
* packageName : com.example.springbatch_8_6_jsonitemreader
* fileName : Customer
* author : namhyeop
* date : 2022/08/11
* description :
* Customer Dto
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/11 namhyeop 최초 생성
*/
@Data
public class Customer {
private Long id;
private String name;
private int age;
}Cursor Based & Paging Based
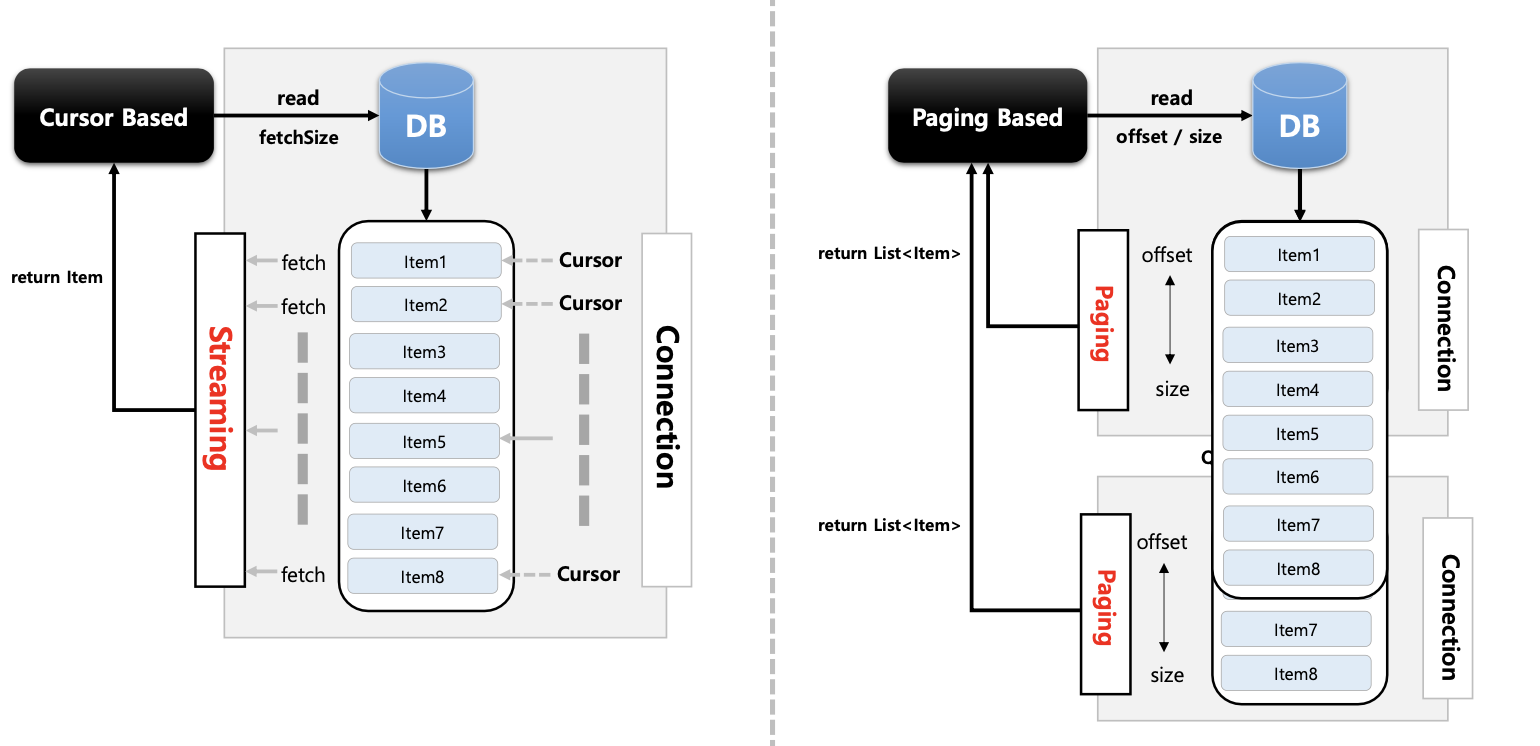
기본개념
- 배치 어플리케이션은 실시간적 처리가 어려운 대용량 데이터를 다루며 이 때 DB I/O 의 성능문제와 메모리 자원의 효율성 문제를 해결할 수 있어야 한다.
- 스프링 배치에서는 대용량 데이터 처리를 위한 두 가지 해결방안을 제시하고 있다
Cursor Based 처리
- JDBC ResultSet 의 기본 메커니즘을 사용
- 현재 행에 커서를 유지하며 다음 데이터를 호출하면 다음 행으로 커서를 이동하며 데이터 반환이 이루어지는 Streaming 방식의 I/O 이다
- ResultSet이 open 될 때마다 next() 메소드가 호출 되어 Database의 데이터가 반환되고 객체와 매핑이 이루어진다.
- DB Connection 이 연결되면 배치 처리가 완료될 때 까지 데이터를 읽어오기 때문에 DB와 SocketTimeout을 충분히 큰 값으로 설정 필요
- 모든 결과를 메모리에 할당하기 때문에 메모리 사용량이 많아지는 단점이 있다
- Connection 연결 유지 시간과 메모리 공간이 충분하다면 대량의 데이터 처리에 적합할 수 있다 (fetchSize 조절)
Paging Based 처리
- 페이징 단위로 데이터를 조회하는 방식으로 Page Size 만큼 한번에 메모리로 가지고 온 다음 한 개씩 읽는다.
- 한 페이지를 읽을때마다 Connection을 맺고 끊기 때문에 대량의 데이터를 처리하더라도 SocketTimeout 예외가 거의 일어나지 않는다
- 시작 행 번호를 지정하고 페이지에 반환시키고자 하는 행의 수를 지정한 후 사용 – Offset, Limit
- 페이징 단위의 결과만 메모리에 할당하기 때문에 메모리 사용량이 적어지는 장점이 있다
- Connection 연결 유지 시간이 길지 않고 메모리 공간을 효율적으로 사용해야 하는 데이터 처리에 적합할 수 있다
JdbcCursorItemReader
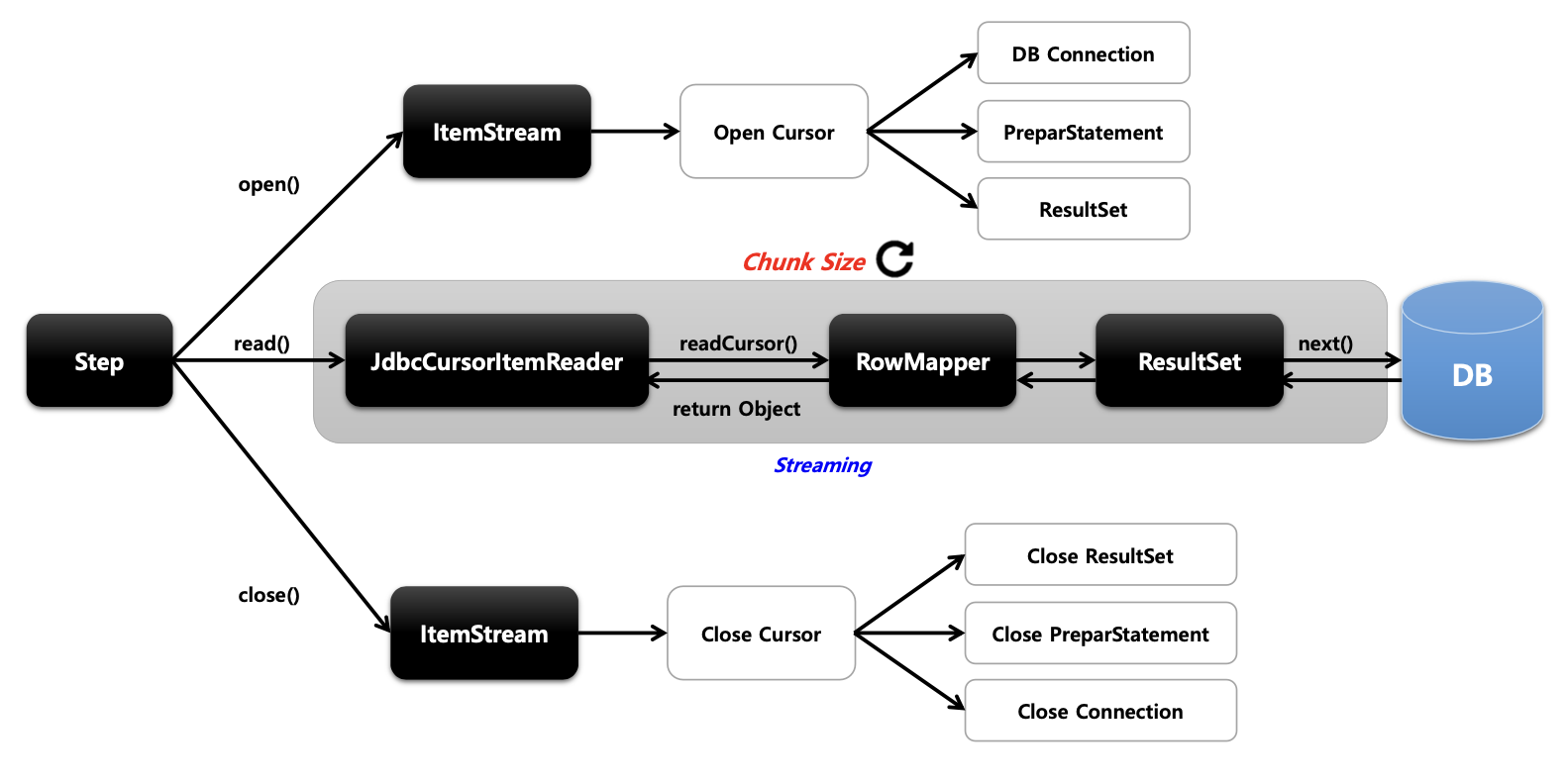
기본개념
- Cursor 기반의 JDBC 구현체로서 ResultSet 과 함께 사용되며 Datasource 에서 Connection 을 얻어와서 SQL 을 실행한다
- Thread 안정성을 보장하지 않기 때문에 멀티 스레드 환경에서 사용할 경우 동시성 이슈가 발생하지 않도록 별도 동기화 처리가 필요하다
API 소개

API 설정
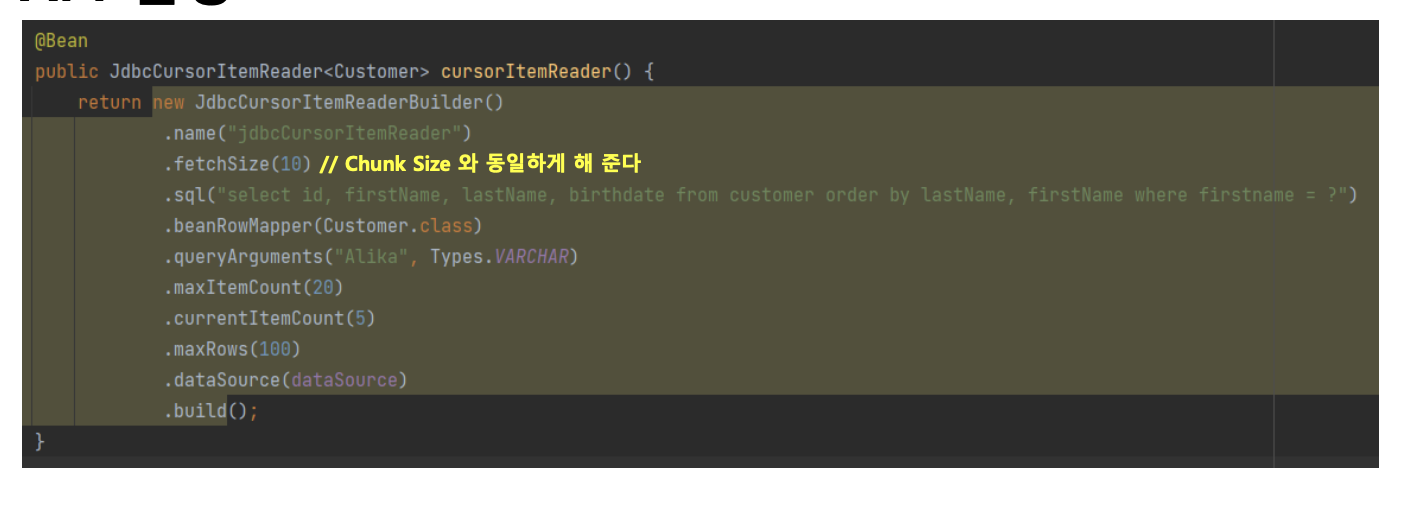
예제코드
package com.example.springbatch_8_7_jdbccursoritemreader;
import lombok.RequiredArgsConstructor;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JdbcCursorItemReader;
import org.springframework.batch.item.database.builder.JdbcCursorItemReaderBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
/**
* packageName : com.example.springbatch_8_7_jdbccursoritemreader
* fileName : JdbcCursorConfiguration
* author : namhyeop
* date : 2022/08/12
* description :
* JdbcCursor 예제
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/12 namhyeop 최초 생성
*/
@RequiredArgsConstructor
@Configuration
public class JdbcCursorConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource;
private int chunkSize = 10;
@Bean
public Job job(){
return jobBuilderFactory.get("batchJob")
.start(step1())
.incrementer(new RunIdIncrementer())
.build();
}
@Bean
public Step step1(){
return stepBuilderFactory.get("step1")
.<Customer, Customer>chunk(chunkSize)
.reader(customItemReader())
.writer(customItemWriter())
.build();
}
@Bean
public JdbcCursorItemReader<Customer> customItemReader() {
return new JdbcCursorItemReaderBuilder<Customer>()
.name("jdbcCursorItemReader")
.fetchSize(chunkSize)
.sql("select id, firstName, lastName, birthdate from customer where firstName like ? order by lastName, firstName")
.beanRowMapper(Customer.class)
.queryArguments("A%")
//조회 시작할 데이터의 위치
.currentItemCount(2)
//조회를 끝낼 데이터의 위치
.maxItemCount(3)
.maxRows(100)
.dataSource(dataSource)
.build();
}
// @Bean
// public JdbcCursorItemReader<Customer> customItemReader() {
// return new JdbcCursorItemReaderBuilder()
// .name("jdbcCursorItemReader")
// .fetchSize(10)
// .sql("select id, firstName, lastName, birthdate from customer where firstName like ? order by lastName, firstName")
// .beanRowMapper(Customer.class)
// .queryArguments("A%")
// .maxItemCount(3)
// .currentItemCount(2)
// .maxRows(100)
// .dataSource(dataSource)
// .build();
// }
private ItemWriter<Customer> customItemWriter() {
return items->{
for (Customer item : items) {
System.out.println(item.toString());
}
System.out.println("=============");
};
}
}package com.example.springbatch_8_7_jdbccursoritemreader;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* packageName : com.example.springbatch_8_7_jdbccursoritemreader
* fileName : Customer
* author : namhyeop
* date : 2022/08/12
* description :
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/12 namhyeop 최초 생성
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Customer {
private Long Id;
private String firstName;
private String lastName;
private String birthdate;
}INSERT INTO `customer` (`id`, `firstName`, `lastName`, `birthdate`)
VALUES (1, "Reed", "Edwards", "1952-08-16 12:34:53"),
(2, "Hoyt", "Park", "1981-02-18 08:07:58"),
(3, "Leila", "Petty", "1972-06-11 08:43:55"),
(4, "Denton", "Strong", "1989-03-11 18:38:31"),
(5, "Zoe", "Romero", "1990-10-02 13:06:31"),
(6, "Rana", "Compton", "1957-06-09 12:51:11"),
(7, "Velma", "King", "1988-02-02 05:52:25"),
(8, "Uriah", "Carter", "1972-08-31 07:32:05"),
(9, "Michael", "Graves", "1958-04-13 18:47:44"),
(10, "Leigh", "Stone", "1967-06-23 23:41:43");
INSERT INTO `customer` (`id`, `firstName`, `lastName`, `birthdate`)
VALUES (11, "Iliana", "Glenn", "1965-02-27 14:33:56"),
(12, "Harrison", "Haley", "1956-06-28 03:15:41"),
(13, "Leonard", "Zamora", "1956-03-28 15:03:09"),
(14, "Hiroko", "Wyatt", "1960-08-22 23:53:50"),
(15, "Cameron", "Carlson", "1969-05-12 11:10:09"),
(16, "Hunter", "Avery", "1953-11-19 12:52:42"),
(17, "Aimee", "Cox", "1976-10-15 12:56:50"),
(18, "Yen", "Delgado", "1990-02-06 10:25:36"),
(19, "Gemma", "Peterson", "1989-04-02 23:42:09"),
(20, "Lani", "Faulkner", "1970-09-18 17:22:14");
INSERT INTO `customer` (`id`, `firstName`, `lastName`, `birthdate`)
VALUES (21, "Iola", "Cannon", "1954-01-12 16:56:45"),
(22, "Whitney", "Shaffer", "1951-03-19 01:27:18"),
(23, "Jerome", "Moran", "1968-03-16 05:26:22"),
(24, "Quinn", "Wheeler", "1979-06-19 16:24:22"),
(25, "Mira", "Wilder", "1961-12-27 12:11:07"),
(26, "Tobias", "Holloway", "1968-08-13 20:36:19"),
(27, "Shaine", "Schneider", "1958-03-08 09:47:10"),
(28, "Harding", "Gonzales", "1952-04-11 02:06:25"),
(29, "Calista", "Nieves", "1970-02-17 13:29:59"),
(30, "Duncan", "Norman", "1987-09-13 00:54:49");
INSERT INTO `customer` (`id`, `firstName`, `lastName`, `birthdate`)
VALUES (31, "Fatima", "Hamilton", "1961-06-16 14:29:11"),
(32, "Ali", "Browning", "1979-03-27 17:09:37"),
(33, "Erin", "Sosa", "1990-08-23 10:43:58"),
(34, "Carol", "Harmon", "1972-01-14 07:19:39"),
(35, "Illiana", "Fitzgerald", "1970-08-19 02:33:46"),
(36, "Stephen", "Riley", "1954-06-05 08:34:03"),
(37, "Hermione", "Waller", "1969-09-08 01:19:07"),
(38, "Desiree", "Flowers", "1952-06-25 13:34:45"),
(39, "Karyn", "Blackburn", "1977-03-30 13:08:02"),
(40, "Briar", "Carroll", "1985-03-26 01:03:34");
INSERT INTO `customer` (`id`, `firstName`, `lastName`, `birthdate`)
VALUES (41, "Chaney", "Green", "1987-04-20 18:56:53"),
(42, "Robert", "Higgins", "1985-09-26 11:25:10"),
(43, "Lillith", "House", "1982-12-06 02:24:23"),
(44, "Astra", "Winters", "1952-03-13 01:13:07"),
(45, "Cherokee", "Stephenson", "1955-10-23 16:57:33"),
(46, "Yuri", "Shaw", "1958-07-14 15:10:07"),
(47, "Boris", "Sparks", "1982-01-01 10:56:34"),
(48, "Wilma", "Blake", "1963-06-07 16:32:33"),
(49, "Brynne", "Morse", "1964-09-21 01:05:25"),
(50, "Ila", "Conley", "1953-11-02 05:12:57");
INSERT INTO `customer` (`id`, `firstName`, `lastName`, `birthdate`)
VALUES (51, "Sharon", "Watts", "1964-01-09 16:32:37"),
(52, "Kareem", "Vaughan", "1952-04-18 15:37:10"),
(53, "Eden", "Barnes", "1954-07-04 01:26:44"),
(54, "Kenyon", "Fulton", "1975-08-23 22:17:52"),
(55, "Mona", "Ball", "1972-02-11 04:15:45"),
(56, "Moses", "Cortez", "1979-04-24 15:26:46"),
(57, "Macy", "Banks", "1956-12-31 00:41:15"),
(58, "Brenna", "Mendez", "1972-10-02 07:58:27"),
(59, "Emerald", "Ewing", "1985-11-28 21:15:20"),
(60, "Lev", "Mcfarland", "1951-05-20 14:30:07");
INSERT INTO `customer` (`id`, `firstName`, `lastName`, `birthdate`)
VALUES (61, "Norman", "Tanner", "1959-07-29 15:41:45"),
(62, "Alexa", "Walters", "1977-12-06 16:41:17"),
(63, "Dara", "Hyde", "1989-08-04 14:06:43"),
(64, "Hu", "Sampson", "1978-11-01 17:10:23"),
(65, "Jasmine", "Cardenas", "1969-02-15 20:08:06"),
(66, "Julian", "Bentley", "1954-07-11 03:27:51"),
(67, "Samson", "Brown", "1967-10-15 07:03:59"),
(68, "Gisela", "Hogan", "1985-01-19 03:16:20"),
(69, "Jeanette", "Cummings", "1986-09-07 18:25:52"),
(70, "Galena", "Perkins", "1984-01-13 02:15:31");
INSERT INTO `customer` (`id`, `firstName`, `lastName`, `birthdate`)
VALUES (71, "Olga", "Mays", "1981-11-20 22:39:27"),
(72, "Ferdinand", "Austin", "1956-08-08 09:08:02"),
(73, "Zenia", "Anthony", "1964-08-21 05:45:16"),
(74, "Hop", "Hampton", "1982-07-22 14:11:00"),
(75, "Shaine", "Vang", "1970-08-13 15:58:28"),
(76, "Ariana", "Cochran", "1959-12-04 01:18:36"),
(77, "India", "Paul", "1963-10-10 05:24:03"),
(78, "Karina", "Doyle", "1979-12-01 00:05:21"),
(79, "Delilah", "Johnston", "1989-03-04 23:50:01"),
(80, "Hilel", "Hood", "1959-08-22 06:40:48");
INSERT INTO `customer` (`id`, `firstName`, `lastName`, `birthdate`)
VALUES (81, "Kennedy", "Hoffman", "1963-10-14 20:18:35"),
(82, "Kameko", "Bell", "1976-06-08 15:35:54"),
(83, "Lunea", "Gutierrez", "1964-06-07 16:21:24"),
(84, "William", "Burris", "1980-05-01 17:58:23"),
(85, "Kiara", "Walls", "1955-12-27 18:57:15"),
(86, "Latifah", "Alexander", "1980-06-19 10:39:50"),
(87, "Keaton", "Ward", "1964-10-12 16:03:18"),
(88, "Jasper", "Clements", "1970-03-05 00:29:49"),
(89, "Claire", "Brown", "1972-02-11 00:43:58"),
(90, "Noble", "Morgan", "1955-09-05 05:35:01");
INSERT INTO `customer` (`id`, `firstName`, `lastName`, `birthdate`)
VALUES (91, "Evangeline", "Horn", "1952-12-28 14:06:27"),
(92, "Jonah", "Harrell", "1951-06-25 17:37:35"),
(93, "Mira", "Espinoza", "1982-03-26 06:01:16"),
(94, "Brennan", "Oneill", "1979-04-23 08:49:02"),
(95, "Dacey", "Howe", "1983-02-06 19:11:00"),
(96, "Yoko", "Pittman", "1982-09-12 02:18:52"),
(97, "Cody", "Conway", "1971-05-26 07:09:58"),
(98, "Jordan", "Knowles", "1981-12-30 02:20:01"),
(99, "Pearl", "Boyer", "1957-10-19 14:26:49"),
(100, "Keely", "Montoya", "1985-03-24 01:18:09");drop table customer;
CREATE TABLE customer(
id mediumint(8) unsigned NOT NULL auto_increment,
firstName varchar(255) default null,
lastName varchar(255) default null,
birthdate varchar(255),
PRIMARY KEY (id)
) AUTO_INCREMENT=1;
select id, firstName, lastName, birthdate from customer where firstName like ? order by lastName, firstName
select * from customer where firstName like ? order by lastName, firstName- maxItemCount가 예제와 약간 다른거 같다. 사용시 유의하자
JpaCursorItemReader
기본개념
- Spring Batch 4.3 버전부터 지원함
- Cursor 기반의 JPA 구현체로서 EntityManagerFactory 객체가 필요하며 쿼리는 JPQL 을 사용한다
API 구조

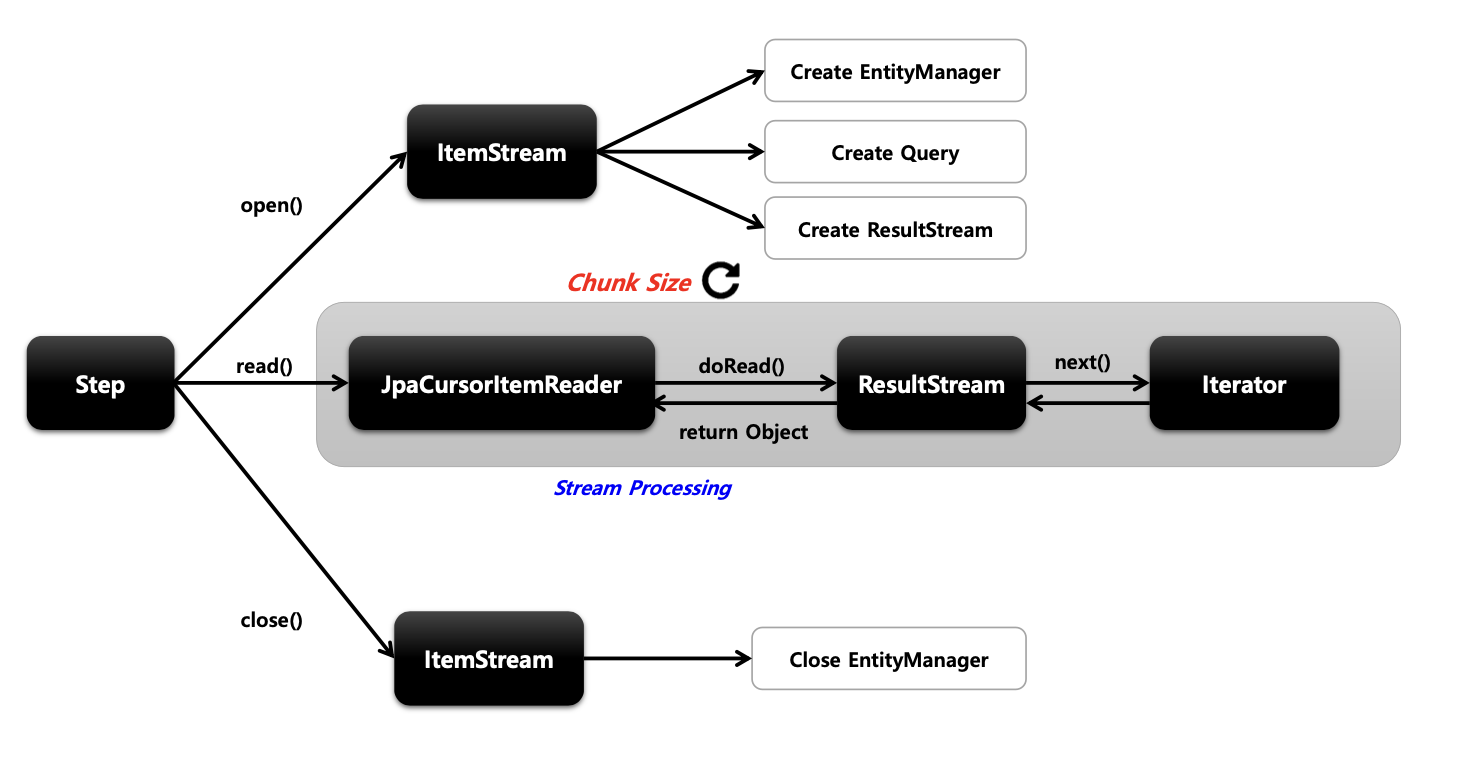
API 설정
예제코드
package com.example.springbatch_8_8_jpacursoritemreader;
import lombok.RequiredArgsConstructor;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JpaCursorItemReader;
import org.springframework.batch.item.database.builder.JpaCursorItemReaderBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.persistence.EntityManagerFactory;
import java.util.HashMap;
import java.util.Map;
/**
* packageName : com.example.springbatch_8_8_jpacursoritemreader
* fileName : JpaCursorConfiguration
* author : namhyeop
* date : 2022/08/12
* description :
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/12 namhyeop 최초 생성
*/
@RequiredArgsConstructor
@Configuration
public class JpaCursorConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory entityManagerFactory;
@Bean
public Job job() {
return jobBuilderFactory.get("batchJob")
.incrementer(new RunIdIncrementer())
.start(step1())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
.<Customer, Customer>chunk(2)
.reader(customItemReader())
.writer(customItemWriter())
.build();
}
@Bean
public ItemReader<? extends Customer> customItemReader() {
/**
* queryString에 첨부할 변수 설정.
* 첫 번째 매개변수는 queryString에 들어갈 변수 이름, 두 번째는 변수 안에 들어갈 내용을 의미
*/
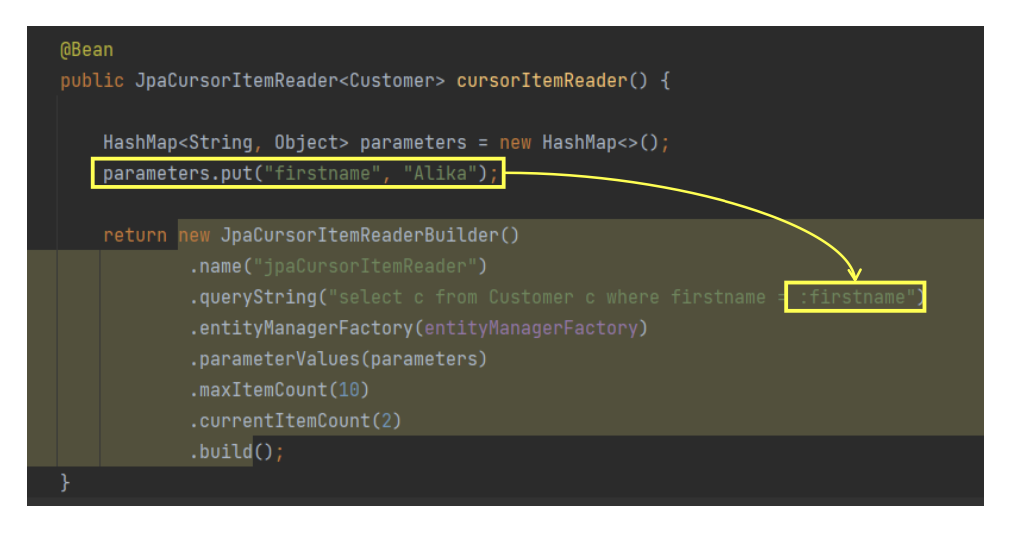
Map<String, Object> parameters = new HashMap<>();
parameters.put("firstName", "A%");
return new JpaCursorItemReaderBuilder<Customer>()
.name("jpaCursorItemReader")
.entityManagerFactory(entityManagerFactory)
.queryString("select c from Customer c where firstName like :firstName")
.parameterValues(parameters)
// .maxItemCount(4)
// .currentItemCount(2)
.build();
}
@Bean
public ItemWriter<Customer> customItemWriter() {
return items -> {
for (Customer item : items) {
System.out.println(item.toString());
}
System.out.println("=================");
};
}
}package com.example.springbatch_8_8_jpacursoritemreader;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
/**
* packageName : com.example.springbatch_8_8_jpacursoritemreader
* fileName : Customer
* author : namhyeop
* date : 2022/08/12
* description :
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/12 namhyeop 최초 생성
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@Entity
public class Customer {
@Id @GeneratedValue
private Long id;
private String firstname;
private String lastname;
private String birthdate;
}JdbcPagingItemReader
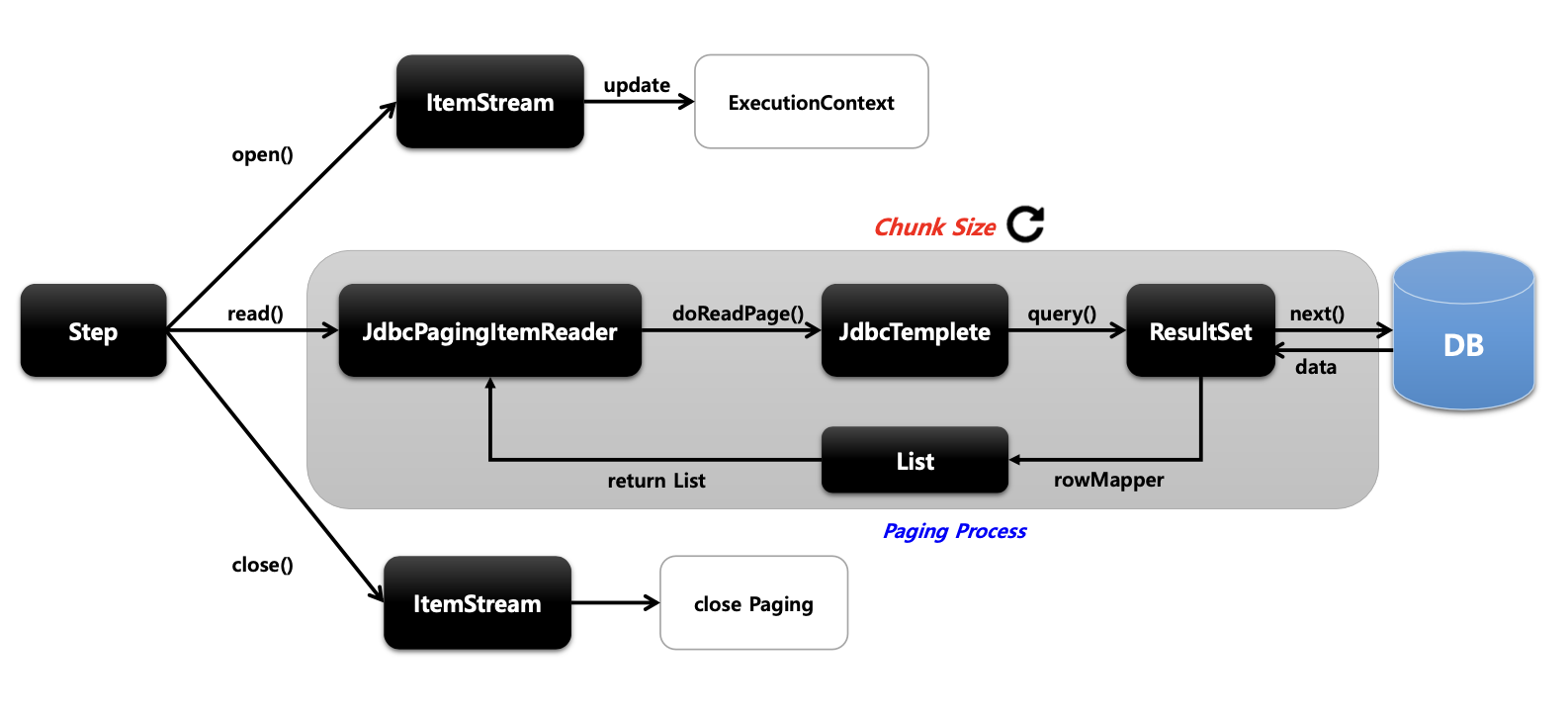
기본개념
- Paging 기반의 JDBC 구현체로서 쿼리에 시작 행 번호 (offset) 와 페이지에서 반환 할 행 수 (limit)를 지정해서 SQL 을 실행한다
- 스프링 배치에서 offset과 limit을 PageSize에 맞게 자동으로 생성해 주며 페이징 단위로 데이터를 조회할 때 마다 새로운 쿼리가 실행한다
- 페이지마다 새로운 쿼리를 실행하기 때문에 페이징 시 결과 데이터의 순서가 보장될 수 있도록 order by 구문이 작성되도록 한다
- 멀티 스레드 환경에서 Thread 안정성을 보장하기 때문에 별도의 동기화를 할 필요가 없다
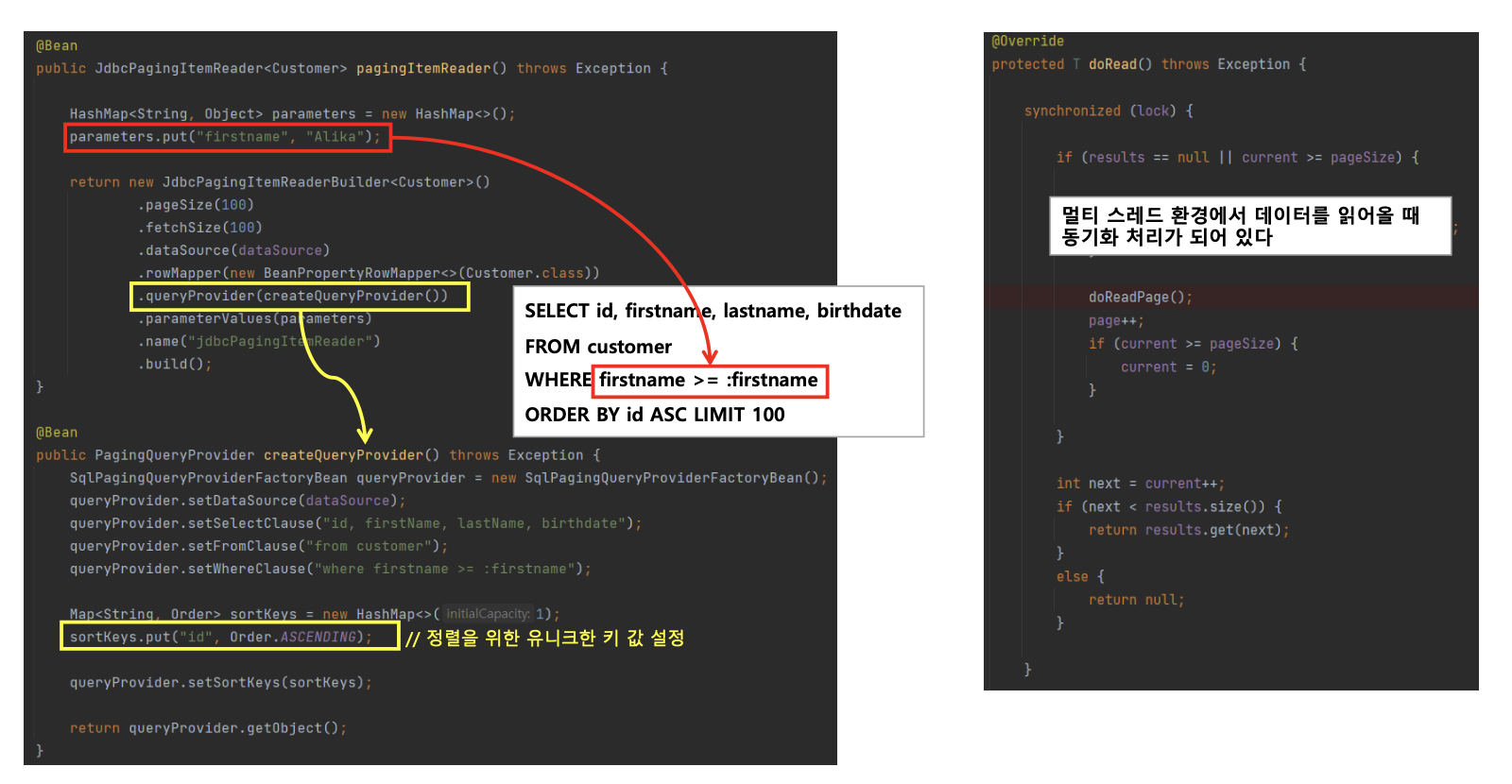
- PagingQueryProvider
- 쿼리 실행에 필요한 쿼리문을 ItemReader 에게 제공하는 클래스
- 데이터베이스마다 페이징 전략이 다르기 때문에 각 데이터 베이스 유형마다 다른 PagingQueryProvider 를 사용한다
- Select 절, from 절, sortKey 는 필수로 설정해야 하며 where, group by 절은 필수가 아니다
API 소개

예제코드
package com.example.springbatch_8_9_jdbcpagingitemreader;
import lombok.RequiredArgsConstructor;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JdbcPagingItemReader;
import org.springframework.batch.item.database.Order;
import org.springframework.batch.item.database.PagingQueryProvider;
import org.springframework.batch.item.database.builder.JdbcPagingItemReaderBuilder;
import org.springframework.batch.item.database.support.SqlPagingQueryProviderFactoryBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
/**
* packageName : com.example.springbatch_8_9_jdbcpagingitemreader
* fileName : JdbcPagingConfiguration
* author : namhyeop
* date : 2022/08/12
* description :
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/12 namhyeop 최초 생성
*/
@RequiredArgsConstructor
@Configuration
public class JdbcPagingConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource;
@Bean
public Job job() throws Exception{
return jobBuilderFactory.get("batchJob")
.incrementer(new RunIdIncrementer())
.start(step1())
.build();
}
@Bean
public Step step1() throws Exception{
return stepBuilderFactory.get("step1")
.<Customer,Customer>chunk(2)
.reader(customItemReader())
.writer(customItemWriter())
.build();
}
@Bean
public JdbcPagingItemReader<Customer> customItemReader() throws Exception{
HashMap<String, Object> parameters = new HashMap<>();
parameters.put("firstName", "A%");
return new JdbcPagingItemReaderBuilder<Customer>()
.name("jdbcPagingItemReader")
//chunksize와 pagesize는 같아야 좋다
.pageSize(2)
//fetchSize는 뭐지?
// .fetchSize(10)
.dataSource(dataSource)
.rowMapper(new BeanPropertyRowMapper<>(Customer.class))
.queryProvider(createQueryProvider())
.parameterValues(parameters)
.build();
}
@Bean
public PagingQueryProvider createQueryProvider() throws Exception {
SqlPagingQueryProviderFactoryBean queryProvider = new SqlPagingQueryProviderFactoryBean();
queryProvider.setDataSource(dataSource);
queryProvider.setSelectClause("id,firstName,lastName,birthDate");
queryProvider.setFromClause("from customer");
queryProvider.setWhereClause("where firstName like :firstName");
Map<String, Order> sortKeys = new HashMap<>();
sortKeys.put("id", Order.ASCENDING);
queryProvider.setSortKeys(sortKeys);
return queryProvider.getObject();
}
@Bean
public ItemWriter<Customer> customItemWriter(){
return items ->{
for (Customer item : items) {
System.out.println(item.toString());
}
System.out.println("======");
};
}
}package com.example.springbatch_8_9_jdbcpagingitemreader;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* packageName : com.example.springbatch_8_9_jdbcpagingitemreader
* fileName : Customer
* author : namhyeop
* date : 2022/08/12
* description :
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/12 namhyeop 최초 생성
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Customer {
private Long id;
private String firstName;
private String lastName;
private String birthdate;
}JpaPagingItemReader
기본개념
- Paging 기반의 JPA 구현체로서 EntityManagerFactory 객체가 필요하며 쿼리는 JPQL 을 사용한다
API 구조

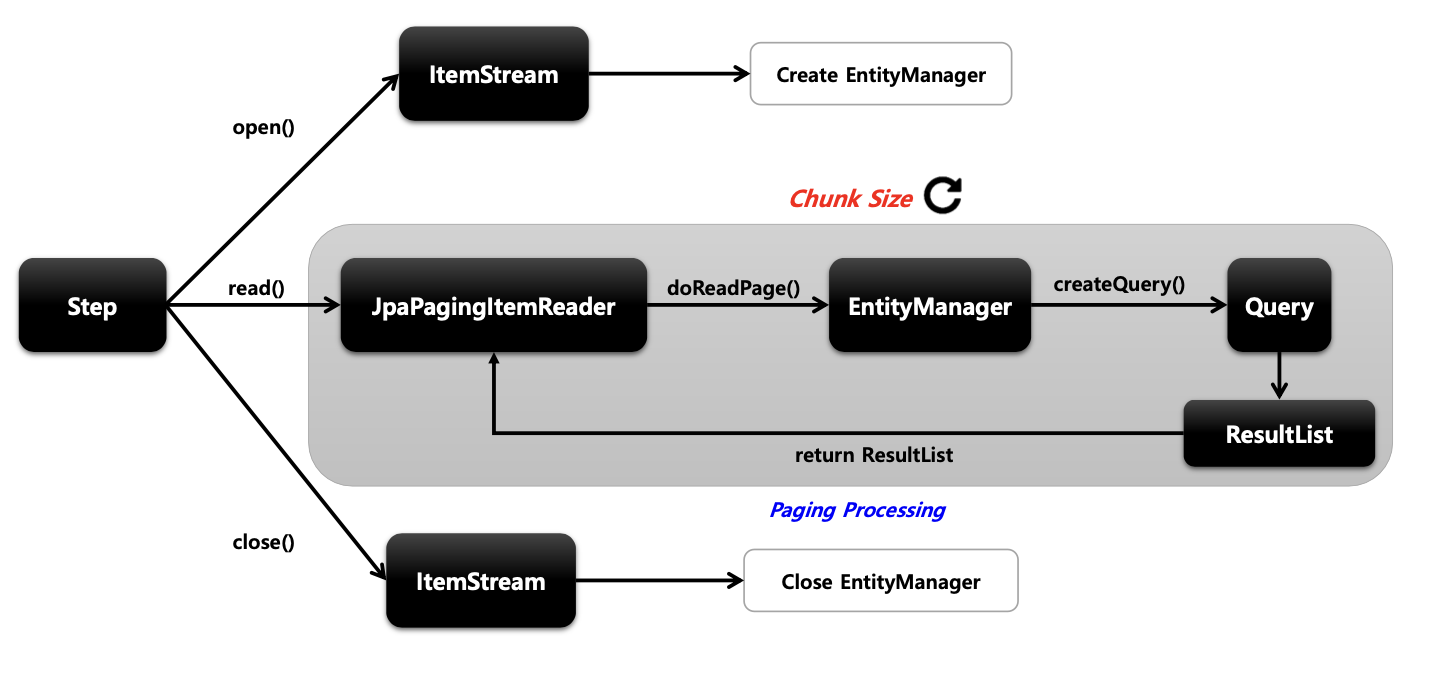
API 설정
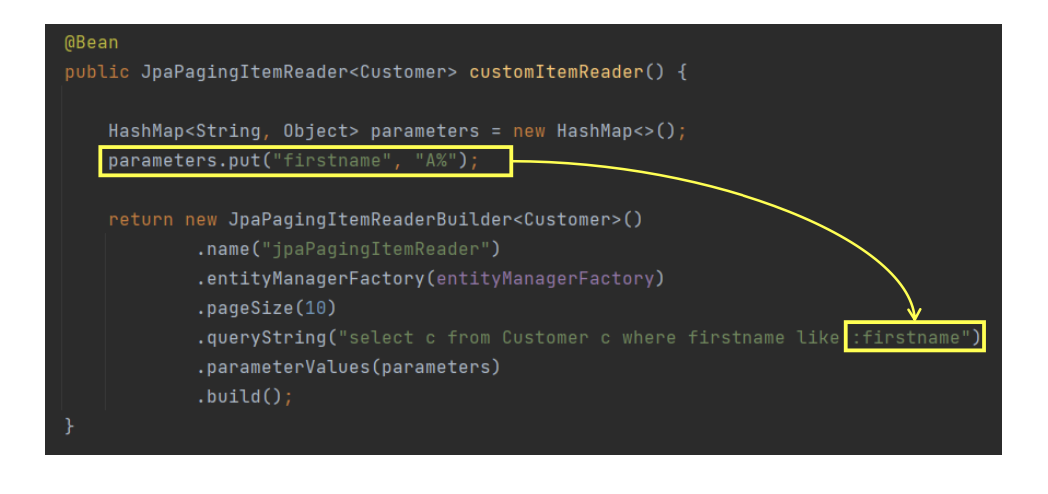
예제코드
package com.example.springbatch_8_10_jpapagingitemreader;
import lombok.RequiredArgsConstructor;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JpaPagingItemReader;
import org.springframework.batch.item.database.builder.JpaPagingItemReaderBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.persistence.EntityManagerFactory;
/**
* packageName : com.example.springbatch_8_10_jpapagingitemreader
* fileName : JpaPagingConfiguration
* author : namhyeop
* date : 2022/08/12
* description :Jpa Paging 예제
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/12 namhyeop 최초 생성
*/
@RequiredArgsConstructor
@Configuration
public class JpaPagingConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory entityManagerFactory;
@Bean
public Job job(){
return jobBuilderFactory.get("batchJob")
.start(step1())
.incrementer(new RunIdIncrementer())
.build();
}
@Bean
public Step step1(){
return stepBuilderFactory.get("step1")
.<Customer, Customer>chunk(10)
.reader(customItemReader())
.writer(customItemWriter())
.build();
}
@Bean
public JpaPagingItemReader<Customer> customItemReader(){
return new JpaPagingItemReaderBuilder<Customer>()
.name("jpaPagingItemReader")
.entityManagerFactory(entityManagerFactory)
.pageSize(10)
.queryString("select c from Customer c join fetch c.address")
.build();
}
@Bean
public ItemWriter<Customer> customItemWriter(){
return items ->{
for (Customer customer : items) {
System.out.println(customer.getAddress().getLocation());
}
};
}
}package com.example.springbatch_8_10_jpapagingitemreader;
import lombok.Data;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import javax.persistence.*;
/**
* packageName : com.example.springbatch_8_10_jpapagingitemreader
* fileName : Address
* author : namhyeop
* date : 2022/08/12
* description :
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/12 namhyeop 최초 생성
*/
@Getter
@Setter
@Entity
public class Address {
@Id @GeneratedValue
private Long id;
private String location;
@OneToOne
@JoinColumn(name = "customer_id")
private Customer customer;
}package com.example.springbatch_8_10_jpapagingitemreader;
import lombok.Getter;
import lombok.Setter;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.OneToOne;
/**
* packageName : com.example.springbatch_8_10_jpapagingitemreader
* fileName : Customer
* author : namhyeop
* date : 2022/08/12
* description :
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/12 namhyeop 최초 생성
*/
@Getter
@Setter
@Entity
public class Customer {
@Id @GeneratedValue
private Long id;
private String username;
private Long age;
@OneToOne(mappedBy = "customer")
private Address address;
}ItemReaderAdapter
기본 개념
- 배치 Job 안에서 이미 있는 DAO 나 다른 서비스를 ItemReader 안에서 사용하고자 할 때 위임 역할을 한다
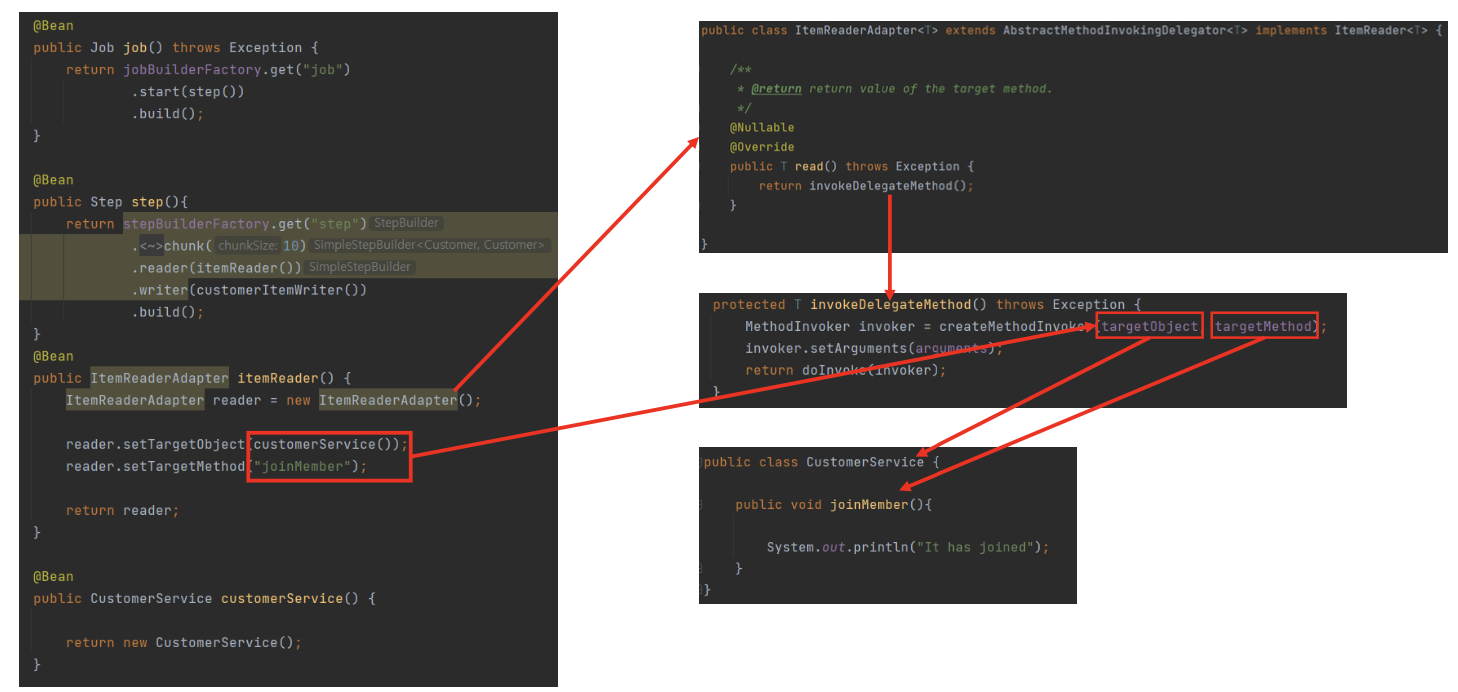
- 그림의 예시가 무슨 의미냐면 ItemReader를 통해서 다른 서비스를 호출하는 예제이다.
- reader를 통해 TargerObject를 CustomerService를 등록하고 실행할 method를 JoinMember를 지정한것을 알 수있다.
- 우측은 실제 Batch의 메소드가 설정되는 핵심 메서드 부분을 캡쳐해온것이다.
예제코드
package com.example.springbatch_8_11_itemreaderadapter;
import lombok.RequiredArgsConstructor;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.adapter.ItemReaderAdapter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* packageName : com.example.springbatch_8_10_itemreaderadapter
* fileName : ItemReaderAdapterConfiguration
* author : namhyeop
* date : 2022/08/13
* description :
* batch 작업중 별도로 등록한 Service를 사용하고 싶을때 사용하는 ItemReader 예제
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/13 namhyeop 최초 생성
*/
@RequiredArgsConstructor
@Configuration
public class ItemReaderAdapterConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job job() {
return jobBuilderFactory.get("batchJob")
.incrementer(new RunIdIncrementer())
.start(step1())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(customItemReader())
.writer(customItemWriter())
.build();
}
@Bean
public ItemReaderAdapter customItemReader() {
ItemReaderAdapter reader = new ItemReaderAdapter();
reader.setTargetObject(customService());
reader.setTargetMethod("joinCustomer");
return reader;
}
@Bean
public ItemWriter<String> customItemWriter(){
return items ->{
System.out.println(items);
};
}
private CustomService<String> customService(){
return new CustomService<>();
}
}package com.example.springbatch_8_11_itemreaderadapter;
/**
* packageName : com.example.springbatch_8_10_itemreaderadapter
* fileName : CustomService
* author : namhyeop
* date : 2022/08/13
* description :
* 예제에서 종료 메소드를 설정 안해줬기 때문에 무한으로 cnt가 증가한다.
* ===========================================================
* DATE AUTHOR NOTE
* -----------------------------------------------------------
* 2022/08/13 namhyeop 최초 생성
*/
public class CustomService<T> {
private int cnt = 0;
public T joinCustomer(){
return(T)("item" + cnt++);
}
}REFERENCE.
https://www.inflearn.com/course/%EC%8A%A4%ED%94%84%EB%A7%81-%EB%B0%B0%EC%B9%98
반응형
'Spring Batch' 카테고리의 다른 글
| 10.Spring Batch의 Chunk와 ItemProcessor (0) | 2024.11.08 |
|---|---|
| 9.Spring Batch의 Chunk와 ItemWriter (1) | 2024.11.08 |
| 7.Spring Batch의 Chunk와 동작원리 살펴보기 (0) | 2024.11.08 |
| 6.Spring Batch의 Flow (1) | 2024.11.07 |
| 5.Spring Batch의 Step (0) | 2024.11.07 |