반응형
개요
- 스키마란 정보를 구성하고 해석하는 것을 도와주는 프레임워크나 개념을 의미합니다.
- 스키마란 개념을 처음 입문하게 되는 계기는 보통 DB를 학습하면서 입니다. DB를 학습하면서 스키마란 데이터베이스의 구조를 정의하고 전반적인 명세와 제약 조건을 기술하는 언어라고 학습하게 됩니다.
- 카프카에서도 스키마란 개념을 활용하여 토픽으로 전송되는 메시지에 대해 미리 스키마를 정의하여 전송함으로서 DB에서 스키마를 활용한 방법과 동일한 효과를 얻을 수 있습니다.
- 카프카에서는 스키마를 활용하기 위해서 스키마 레지스트리라는 개념이 필요합니다. 따라서 이번 글에서는 스키마 레지스트리에 대한 글을 작성해보도록 하겠습니다.
스키마의 개념과 유용성
- 스키마 레지스트리를 설명하기전에 관계형 데이터베이스(RDB)에서 스키마에 대해 설명하겠습니다.
- 데이터를 RDB에 Insert할 때 스키마를 사전에 정의함으로서 스키마에 정의된 내용과 다른 데이터를 추가하려고 시도하면 작업은 실패하게 됩니다.
- 스키마를 정의함으로써 RDB는 지속적으로 약속된 형식으로 데이터를 Insert하기에 이후 Server에서 데이터를 가지고 작업(파싱, 로직 구현 등)을 진행할 때 개발자는 어떤 형식으로 들어올지 미리 알 수 있습니다. 즉 스키마는 어떤 형식으로 데이터를 받을지에 대한 약속이라고 볼 수 있습니다.
- 카프카에서도 end-point간의 메시지를 주고 받을때 카프카에서 설정한 스키마의 정보를 기반으로 메시지를 주고 받는다면 안정적인 서비스를 운영하는데 도움이 됩니다.
카프카와 스키마 레지스트리
- 카프카에서 스키마를 활용하는 방법은 스키마 레지스트리라는 별도의 애플리케이션을 이용하는 것입니다. 스키마라는 추상적인 개념을 다루기 위한 도구이자 애플리케이션이 스키마 레지스트리입니다.
- 스키마 레지스트리는 아래와 같이 동작합니다.
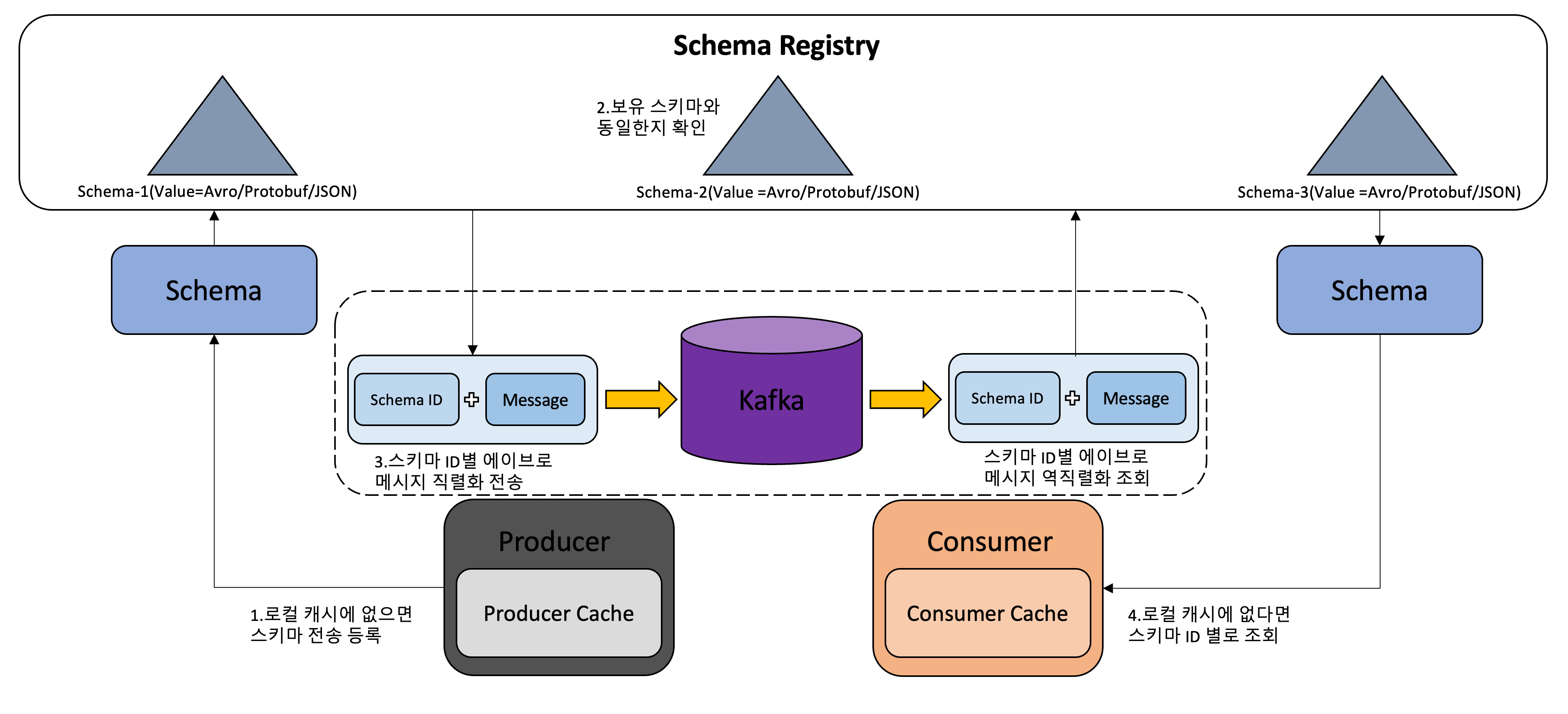
- 에이브로 프로듀서를 사용하며 컨플루언트에서 제공하는 io.confluent.kafka.serializers.kafkaAvroserializer라는 새로운 직렬화를 사용해 전송하려는 메시지의 스키마 타입이 로컬 캐시에 존재하는지 확인한 이후 존재하면 로컬 캐시에 등록된 정보를 사용하고 없다면 스키마 레지스트리에 스키마가 존재하는지 여부를 확인합니다. 만약 스키마 레지스트리에 스키마가 확인되지 않을 경우 에이브로 프로듀서는 스키마를 스키마 레지스트리에 등록하고 캐시합니다. 이후 스키마 레지스트리는 저장된 스키마의 정보를 카프카의 내부 토픽에 저장합니다.
- 스키마 레지스트리에서는 프로듀서가 요청한 ID의 스키마의 버전과 보유한 스키마의 버전이 동일한지를 확인합니다. 스키마 레지스트리는 자체적으로 각 스키마에 고유 ID를 할당하는데 이 ID는 순차적으로 1씩 증가하지만 반드시 연속적이지는 않습니다. 스키마가 삭제될수도 있기 때문입니다. 이후 스키마 레지스트리는 프로듀서에게 고유 ID를 응답합니다.
- 프로듀서는 스키마 레지스트리로부터 받은 스키마 ID를 활용하여 메시지를 카프카로 전송합니다. 이때 프로듀서는 스키마의 전체 내용이아닌 오로지 메시자와 스키마 ID만 전송합니다. JSON은 Key,Value 형태로 전체 메시지를 전송하지만 에이브로를 사용하면 프로듀서가 스키마 ID와 Value만 메시지로 보내게 되어 카프로 전송하는 전체 메시지의 크기를 줄일 수 있으며 이는 JSON보다 에이브로를 사용하는 편이 더 효율적인 이유입니다.
- 에이브로 컨슈머는 스키마 ID로 컨플루언트에서 제공하는 io.confluent.kafka.serializers.KafkaAvroDeserializer라는 새로운 역직렬화를 사용하여 카프카에 저장된 메시지를 읽습니다. 이때 컨슈머가 스키마 ID를 가지고 있지 않다면 스키마 레지스트리로부터 가져옵니다.
- 카프카의 스키마 레지스트에 가장 최적화된 데이터 직렬화 방식은 에이브로(Avro)입니다.
💡
카프카는 데이터 직렬화시 JSON, 프로토콜 포맷도 지원합니다. 그중에 에이브로 방식을 가장 추천하는 이유는 JSON과 매핑되며 JSON과 다르게 필드 네임이 포함되어 전송되지 않고 바이너리 데이터 포맷 형태로 전송되어 속도 측면에서 가장 빠릅니다.
- Avro는 데이터 직렬화 및 역직렬화를 위한 프레임워크이며, 이를 통해 데이터를 이진 형식으로 변환할 수 있습니다. Avro는 스키마 기반 직렬화 방식으로, 데이터에 대한 스키마를 미리 정의하고 해당 스키마를 사용하여 데이터를 직렬화하고 역직렬화합니다. 스키마는 Avro의 핵심 개념이며, 데이터의 구조와 필드 유형을 정의하는데 사용됩니다.
- Kafka에서 Avro를 사용하면 메시지를 보내고 받는 클라이언트 간에 데이터 형식을 일관되게 유지할 수 있습니다. 스키마 레지스트리는 클라이언트가 공유하는 중앙 스키마 저장소로, Avro 스키마를 등록하고 버전 관리를 할 수 있습니다. 클라이언트는 스키마 레지스트리를 통해 메시지의 스키마를 검색하여 데이터를 직렬화 및 역직렬화할 수 있습니다.
- 아래는 에이브로를 활용한 스키마 정의 파일 예시입니다.
{
"namespace" : "kafkaSchemaRegistry.info", //이름을 식별하는 문자열 입니다,
"type" : "record", //에이브로는 record, enums, arrays, map 등을 지원합니다. 예시에서는 record로 설정하였습니다.
"doc" : "this is am example doc ", // 사용자들에게 해당 스키마가 어떤 스키마인지에 대한 정보를 제공하는 주석란입니다.
"name": "exampleName", //레코드의 이름을 나타내는 문자열입니다,
//fileds는 JSON 배열을 의미하여 필드들의 리스트를 기술하는 영역입니다.
//아래 영역에서 필드 이름을 정의하여 key,value 형식으로 입력하면 됩니다. type란은 boolean, int, long, string 등의 타입을 정하는곳이며 doc은 주석을 입력하는곳입니다.
"fields" : [
{"techName1": "이 부분은 필드의 이름을 기술하는 영역입니다.", "type": "string", "doc": "이 부분은 주석을 입력하는 곳입니다." },
{"techName2": "이 부분은 필드의 이름을 기술하는 영역입니다.", "type": "string", "doc": "이 부분은 주석을 입력하는 곳입니다." }
]
}- JSON과 다르게 주석을 입력하는 영역이 있어서 사용자에게 어떤 의미로 데이터를 전송하는것인지를 명시할 수 있습니다.
💡
스키마 관리 목적으로 사용되는 메시지는 순서가 중요하므로 Schemas 토픽의 파티션 수는 항상 1입니다.
스키마 레지스트리의 장점
- 위에서 스키마 레지스트리는 프로듀서와 컨슈머가 직접 스키마를 주고 받는 통신을 하지는 않지만 프로듀서와 컨슈머 각자 스키마 레지스트리와 통신하면서 스키마의 정보를 주고받는것을 확인했습니다.
- 프로듀서가 스키마 정보를 스키마 레지스트리에 등록함으로써 프로듀서가 카프카를 메시지로 전송할 때 메시지의 크기를 줄일 수 있었고 컨슈머가 카프카로부터 메시지를 읽을 때도 메시지의 크기를 줄일 수 있었습니다.
- 나아가 스키마 레지스트리를 사용하는 프로듀서와 컨슈머 측면에서 적은 네트워크 대역폭을 사용해 메시지를 전송한다는 이득도 존재합니다.
- 마지막으로 사전에 정의되지 않은 형식의 메시지는 전송할수 없으므로 데이터리를 처리하는 쪽에서 협의되지 않은 메시지가 들어오는 경우를 사전에 방지할 수 있습니다.
스키마 레지스트리 호환성
- 앞선 글에서 스키마는 버전이 업데이트 될 수 있다는것을 확인했습니다. 도메인 바뀔수 있고 그에 따라 스키마의 형태는 수정될 수 있기 때문입니다.
- 수정 될때마다 스키마 레지스트리에서는 스키마에 새로운 ID를 발급합니다.
- 이때 만약 프로듀서가 컨슈머가 채택한 스키마의 버전보다 전 단계인 스키마의 형태에 맞춰 메시지를 보내게 될 경우 해당 메시지를 소비할지 말지를 결정해야 하는데 이러한 기준이 되는 속성값이 호환성입니다.
- 호환성에는 BACKWARD, FORWARD, FULL 3가지 존재합니다.
BACKWARD 호환성
- BACKWARD 호환성이란 버전 업데이트된 스키마를 적용한 컨슈머가 버전 업데이트가 안된 스키마를 적용한 프로듀서가 보낸 메시지를 읽을 수 있도록 허용하는 호환성을 의미합니다.

- 위와 같은 그림에서 버전3 스키마로 업데이트된 설정을 가지고 있는 컨슈머가 버전3 스키마를 가지고 있는 프로듀서가 전송하는 메시지를 소비하는것은 당연합니다.
- 하지만 이전 버전인 버전2 스키마를 가지고 있는 프로듀서의 메시지도 소비할 수 있도록 설정하는 호환성이 BACKWARD 호환성입니다.
- 만약 컨슈머가 모든 버전의 스키마를 호환하고자 한다면 BACKWORD_TRANSITIVE를 설정하면 됩니다.
| 호환성 레벨 | 지원버전(컨슈머 기준) (예: 현재 최신 스키마 버전이 3인 경우) | 변경 허용 항목 | 스키마 업데이트 순서 |
|---|---|---|---|
| BACKWORD | 자신과 동일한 버전과 하나 아래의 하위 버전 | 필드 삭제, 기본 값이 지정된 필드 추가 | 컨슈머 → 프로듀서 |
| BACKWORD_TRANSITIVE | 자신과 동일한 버전을 포함한 모든 하위 버전 | 필드 삭제, 기본 값이 지정된 필드 추가 | 컨슈머 → 프로듀서 |
FORWARD 호환성
- FORWARD 호환성이란 버전 업데이트된 스키마를 적용한 프로듀서가 버전 업데이트가 안된 스키마를 적용한 컨슈머가 보낸 메시지를 읽을 수 있도록 허용하는 호환성을 의미합니다.
- BACKWARD 호환성이 컨슈머 기준의 시점이었더라면 FORWARD는 프로듀서 기준의 시점이라고 볼 수 있습니다.
- 제 생각에는 컨슈머가 프로듀서보다 플로우가 뒤에 있기 때문에 BACKWARD라는 명칭이 붙고 반대로 프로듀서는 FORAWRD라는 명칭이 붙은것 같습니다.

- 위 그림의 예시대로 프로듀서가 버전 3 스키마를 전송하면 컨슈머가 버전3 스키마를 소비하는것은 당연하지만 컨슈머가 버전2 메시지를 소비할 수도 있도록 하는 설정입니다.
- 만약 컨슈머가 모든 버전의 스키마를 호환하고자 한다면 FORWARD_TRANSITIVE를 설정하면 됩니다.
| 호환성 레벨 | 지원버전(컨슈머 기준) (예: 현재 최신 스키마 버전이 3인 경우) | 변경 허용 항목 | 스키마 업데이트 순서 |
|---|---|---|---|
| FORWARD | 자신과 동일한 버전과 하나 위의 상위 버전(버전2로 버전3도 처리 가능) | 필드 추가, 기본 값이 지정된 필드 삭제 | 프로듀서 → 컨슈머 |
| FORWARD_TRANSITIVE | 자신과 동일한 버전을 포함한 모든 상위 버전(버전2로 버전3과 그 이상 처리 가능) | 필드 추가, 기본 값이 지정된 필드 삭제 | 프로듀서 → 컨슈머 |
FULL 호환성
- FULL 호환성은 BACKWARD와 FORWARD 호환성 모두를 지원하는 방식입니다.
- 앞서 살펴본 BACKWARD와 FORWARD 호환성에 비해 제약없이 편리하게 사용 가능합니다.
- 최근 2개(+1, -1)의 버전 스키마를 지원하는것으로 이해하면 될 거 같습니다.
호환성 레벨 지원버전(컨슈머 기준) (예: 현재 최신 스키마 버전이 3인 경우) 변경 허용 항목 스키마 업데이트 순서 FULL 자신과 동일한 버전과 하나 위 또는 아래 버전(버전2로 버전1 또는 버전3도 처리 가능) 기본값이 지정된 필드 추가, 기본 값이 지정된 필드 삭제 순서 상관 X FULL_TRANSITIVE 자신과 동일한 버전을 포함한 모든 상위 버전(버전과 무관하게 모든 버번 처리 가능) 기본값이 지정된 필드 추가, 기본 값이 지정된 필드 삭제 순서 상관 Xㅋ
💡
스키마 호환성의 스키마 업데이트 순서는 반드시 지켜야 합니다. 그렇지 않다면 null값 또는 default값이 전달되어 사용자가 원했던 개발 로직으로 실행되지 않습니다.
정리
- 스키마 레지스트리를 활용한다면 내부적으로 메시지를 어떤 규약으로 전송할지에 대한 약속을할 수 있다.
- 개발자는 전달받는 메시지의 규약이 정해져있기 때문에 파싱, 구현 로직을 작성할 때 오류를 방지할 수 있다.
- 스키마의 히스토리가 내부 주석으로 관리되기 때문에 관리에 용이하다.
- 스키마 레지스트리 호환성을 통해 프로듀서와 컨슈머가 버전이 다른 메시지를 어떻게 수용할지에 대한 정책을 결정할 수 있다.
반응형
'Kafka' 카테고리의 다른 글
| Kafka에서 정확한 한 번을 지원하는 방법 (1) | 2024.11.12 |
|---|---|
| 컨슈머의 내부 동작 원리(컨슈머 오프셋, 그룹코디네이터, 스태틱 맴버십,파티션 할당 전략) (0) | 2023.06.01 |
| 프로듀서의 내부 동작 원리(파티셔너, 배치) (0) | 2023.06.01 |
| 카프카의 내부 동작 원리(리플리케이션,리더, 팔로워, 리더에포크, 컨트롤러,로그) (1) | 2023.06.01 |
| 카프카 기본 개념과 구조 (0) | 2023.06.01 |